find_next_zero_bit
unsigned long find_next_zero_bit(const unsigned long *addr,

unsigned long size,
unsigned long offset)
unsigned long offset)
这个函数的用意是在addr开始的地址段中,找到一个为0的位,函数调用成功则返回该位的索引,如果没找到,则返回size。所以可以看出搜索范围并不包含size这个点,因为即便size这个点为0,满足要求,但其返回值和失败时的返回值是相同的,所以也看作是失败。
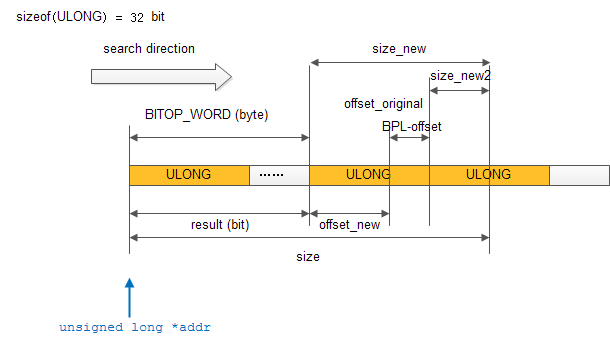
搜索示意图如下:
再分析代码:
unsigned long find_next_zero_bit(const unsigned long *addr, unsigned long size,
unsigned long offset)
{
const unsigned long *p = addr + BITOP_WORD(offset);
unsigned long result = offset & ~(BITS_PER_LONG-1); // result如上图,搜索起始点所在ULONG之前所有的bit
unsigned long tmp;
if (offset >= size)
return size;
size -= result; // 扣掉result,即size_new
offset %= BITS_PER_LONG; // 取得所在ULONG中的偏移量,即offset_new
if (offset) {
tmp = *(p++);
tmp |= ~0UL >> (BITS_PER_LONG - offset); // 将offset之内的bit全部置1,参看图1
if (size < BITS_PER_LONG) // 这表示搜索范围在一个ULONG范围之内,参看图2
goto found_first;
if (~tmp) // tmp至少有一个0位,即tmp的BPL - offset这一段中至少有一个0。
unsigned long offset)
{
const unsigned long *p = addr + BITOP_WORD(offset);
unsigned long result = offset & ~(BITS_PER_LONG-1); // result如上图,搜索起始点所在ULONG之前所有的bit
unsigned long tmp;
if (offset >= size)
return size;
size -= result; // 扣掉result,即size_new
offset %= BITS_PER_LONG; // 取得所在ULONG中的偏移量,即offset_new
if (offset) {
tmp = *(p++);
tmp |= ~0UL >> (BITS_PER_LONG - offset); // 将offset之内的bit全部置1,参看图1
if (size < BITS_PER_LONG) // 这表示搜索范围在一个ULONG范围之内,参看图2
goto found_first;
if (~tmp) // tmp至少有一个0位,即tmp的BPL - offset这一段中至少有一个0。
goto found_middle;
size -= BITS_PER_LONG;
result += BITS_PER_LONG;
}
while (size & ~(BITS_PER_LONG-1)) { // 不断遍历size前的ULONG
if (~(tmp = *(p++)))
goto found_middle;
result += BITS_PER_LONG;
size -= BITS_PER_LONG;
}
if (!size) // 当size正好是整数个ULONG时,如果没找着,返回值就是原始的size,若不是,会依次进found_first,然后found_middle
return result;
tmp = *p;
found_first:
tmp |= ~0UL << size; // 将size以上部分全部置1
size -= BITS_PER_LONG;
result += BITS_PER_LONG;
}
while (size & ~(BITS_PER_LONG-1)) { // 不断遍历size前的ULONG
if (~(tmp = *(p++)))
goto found_middle;
result += BITS_PER_LONG;
size -= BITS_PER_LONG;
}
if (!size) // 当size正好是整数个ULONG时,如果没找着,返回值就是原始的size,若不是,会依次进found_first,然后found_middle
return result;
tmp = *p;
found_first:
tmp |= ~0UL << size; // 将size以上部分全部置1
if (tmp == ~0UL) // offset~size或head~size之间没有0
return result + size; // 返回值即为传入的size
found_middle:
return result + ffz(tmp); // ffz就是寻找unsigned long变量的第一个0位索引的宏
}
return result + size; // 返回值即为传入的size
found_middle:
return result + ffz(tmp); // ffz就是寻找unsigned long变量的第一个0位索引的宏
}