Resource_Access_Protocol - PIP, PCP, SRP
常见的protocol有Non Preemption Protocol (NPP),Highest Locker’s Priority Protocol (HLP),Priority Inheritance Protocol (PIP,优先级继承),Priority Ceiling Protocol (PCP,优先级天花板),Stack-based Resource Policy (SRP)。后3者应用比较多,且他们呈现递进关系,PCP是PIP的改进,SRP是PCP的改进。本文主要针对PIP,PCP和SRP。
问题
Unbounded Priority Inversion
简单的优先级反转。
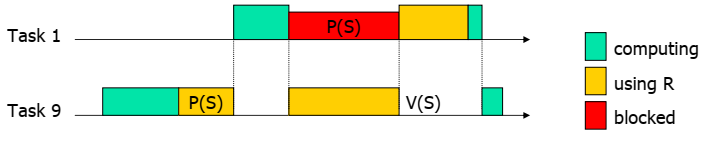
引入任务抢占后,优先级反转会导致不可预测的等待时间。这称为Unbounded Priority Inversion。
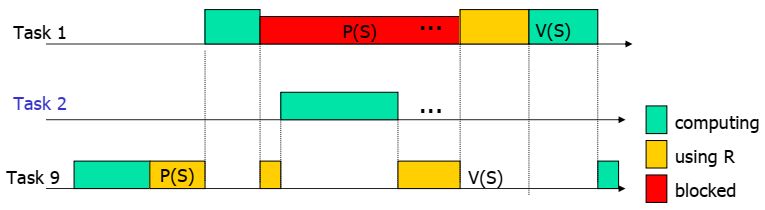
Dead lock
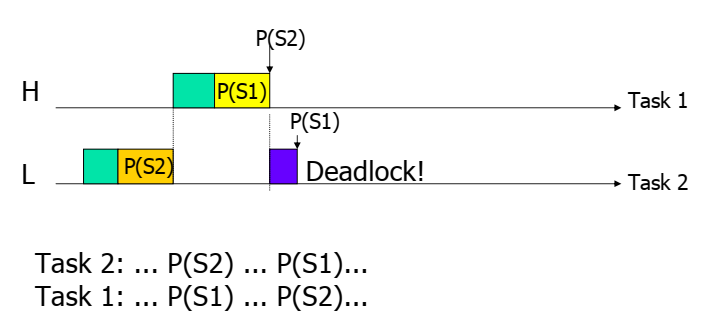
当有多个任务要请求多个资源的时候,则很有可能出现死锁的情况。
Transitive blocking
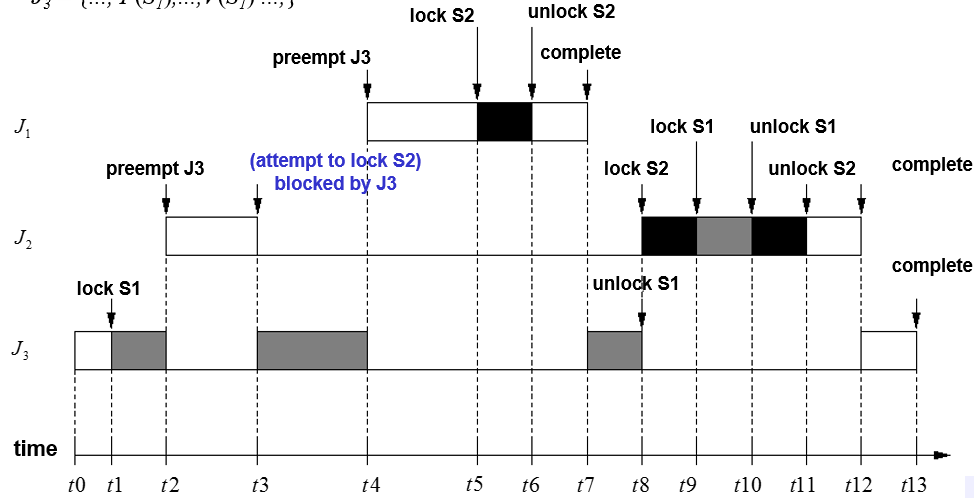
阻塞的传递,看下图
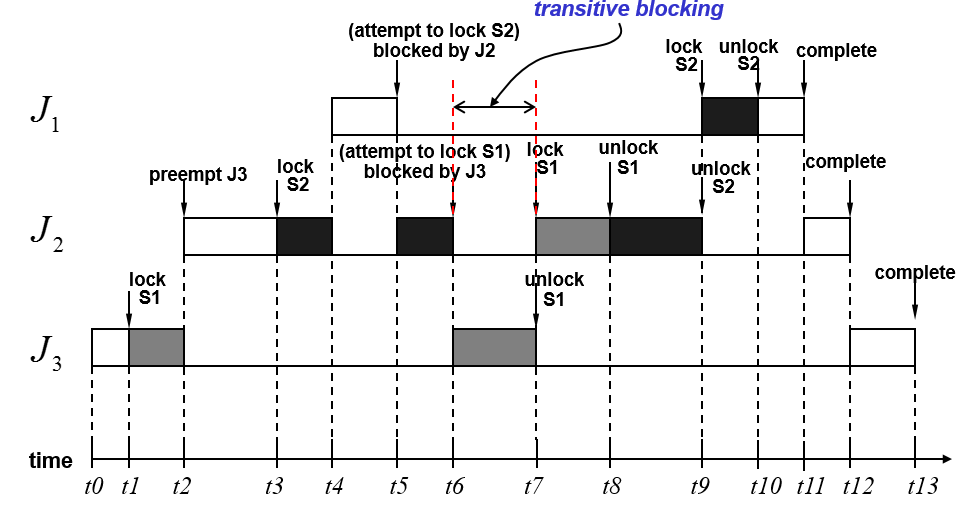
当有嵌套临界区的时候,就很容易产生阻塞传递。J1被J2阻塞因为S2,J2被J3阻塞因为S1,导致J1必须等待J3释放S1,然后J2释放S2之后,才可以顺利获得S2进入临界区。
Schedulability
PIP
定义
- direct blocking:普通的资源竞争。当一个任务申请的资源被另一个任务锁住时,即是direct blocking。
- push-through blocking: 因为priority inversion导致的阻塞。
算法
- A gets semaphore S
- B with higher priority tries to lock S, and blocked by S
- B transfers its priority to A (so A is resumed and run with B’s priority)
- A finishes its critical section and back to original priority before it enters the critical section
优点
因为当前占住资源的任务,始终以最高优先级在运行,中等优先级的任务就不可能抢占低优先级任务,所以解决了Unbounded Priority Inversion。
缺点
- PIP并不能解决死锁问题。
- PIP也不能解决阻塞传递的问题。
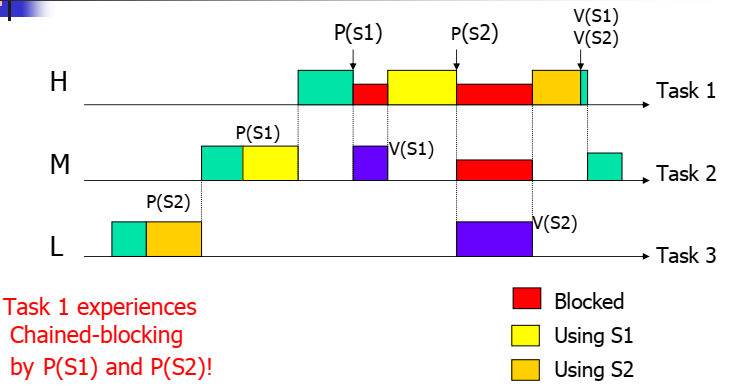
- PIP还有不够完善的地方是在处理多次资源请求时,每一次资源请求都可能被block,导致过多的context switch。如下的Task1。
PCP
PCP算法只能适用于binary semaphore场景。
定义
- 一个semaphore的ceiling是所有可能lock它的线程的最高优先级
- 某一时刻,针对某一任务J的ceiling是,除J以外的其他线程已lock的semaphore的ceiling最大值
- ceiling blocking: 因为优先级不大于系统优先级天花板导致的阻塞
- S∗: 导致ceiling blocking的信号量
- π(J): 任务J的优先级
- C(S): 信号量S的优先级天花板
- π(J): 系统针对J的优先级天花板
算法
- 当某一任务J需要lock一个semaphore时
- 若该资源已被J′ lock
- π(J)≤π(J′),则J被block
- π(J)>π(J′),则J′获得J的优先级,直到J′释放该资源
- 若该资源free
- π(J)≤π(J),则J被S∗阻塞,因为π(J)≤C(S∗),所以不会发生优先级继承
- π(J)>π(J),则J可以锁住该资源
- 若该资源已被J′ lock
- 如果一个任务不涉及申请资源,则它可以正常抢占(preempt)其他低优先级任务。
OCPP vs. ICPP
OCPP = Original Ceiling Priority Protocol, ICPP = Immediate Ceiling Priority Protocol
Wiki词条Priority ceiling protocol中提到这两种算法,OCPP就是Lui Sha et.在[3]中提到的算法。ICPP是OCPP的一个变种。在[5]中称之为Highest Locker’s Priority Protocol (HLP) 。Wiki上称:
The worst-case behaviour of the two ceiling schemes is identical from a scheduling view point. Both variants work by temporarily raising the priorities of tasks.
ICPP的基本算法是:
In ICPP, a task's priority is immediately raised when it locks a resource. The task's priority is set to the priority ceiling of the resource, thus no task that may lock the resource is able to get scheduled.
不明白后半句是啥意思,相同优先级的线程应该是可以得到轮转运行的,除非,禁止round robin
ICPP与OCPP的不同之处在于:
- ICPP is easier to implement than OCPP, as blocking relationships need not be monitored
- ICPP leads to fewer context switches as blocking is prior to first execution
- ICPP requires more priority movements as this happens with all resource usage
- OCPP changes priority only if an actual block has occurred
看起来ICPP唯一的问题是会带来频繁的调整优先级,OCPP只在发生blocking的时候调整
优点
- 因为PCP包含PIP,所以PCP包含PIP所有的优点
- PCP可以解决死锁问题。
证明
再看这张图
此时有:
C(S1)=H,C(S2)=H
当Task1试图执行P(S1)时,π(Task1)=C(S2)=H,显然π(Task1)≤π(Task1),不能获取S1,被阻塞,也就不会有后来的P(S2)了。
当Task2试图执行P(S2)时,π(Task2)=0,因为除了Task2,没有其他的资源被锁住。所以Task2可以顺利获得资源S1。
综上,死锁不可能发生。
- 没有阻塞传递。
证明
假设J3阻塞J2, J2阻塞J1
t3时,C(S1)≥π(J2)⋂C(S1)≥π(J3),J2 lock成功,说明π(J2)>C(S1),矛盾。正确的图如下:
成功避免transitive blocking。
- 被低优先级任务阻塞(priority inversion)只会发生一次
证明
假设有π(J1)>π(J2)
- 如果J1被J2阻塞两次,分别在J1申请资源A,B时,则有
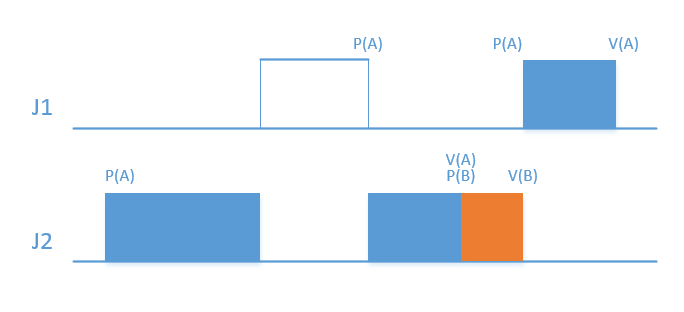
这种情况不可能发生,因为当A被释放时(V(A)),因为J1是高优先级任务,A一旦释放,J1则会立即得到运行
- 如果J1被不同的任务J2,J3阻塞
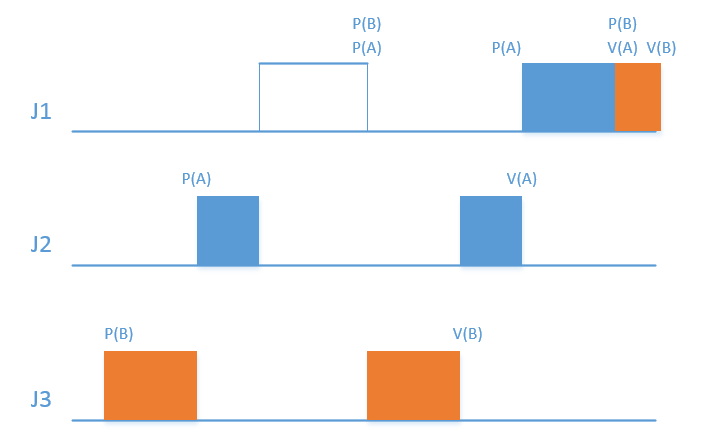
- J1对A,B有诉求,说明π(J1)≤C(A)⋂π(J1)≤C(B)
- J2能得到运行,说明π(J2)>π(J2)≥C(B)
- 综上,两者矛盾,因为π(J2)<π(J1)。所以如果J1对B有诉求,则J2在申请A的时候会被阻塞(ceiling blocking),因为π(J2)≥C(B)≥π(J1)>π(J2),即π(J2)<π(J2)
- PCP不用考虑PIP中的链式调整的问题
PIP中的链式调整如下图:
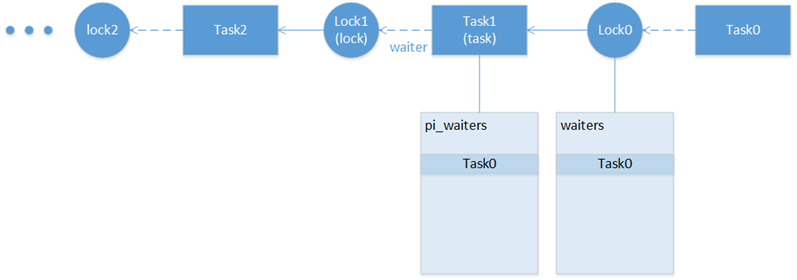
假如Task0对Lock0的申请,提升了Task1的优先级,则如果Task1已经因为申请Lock1,提升了Task2的优先级,则此时需要同步调整。但是在PCP中这一链条不存在。
考虑Task0来申请Lock0的时候,需要提升Task1的优先级,如果链条要成立则:
- π(Task0)>π(Task1)>π(Task2)>…
- owner(Lock1) = Task2, owner(Lock0) = Task1
- Task1 is in Lock1 waiter list
考虑下面两种情况:
- 当Task1要占住Lock0时,若Task2已经占住Lock1,则π(Task2)>C(Lock1),因为Task1对Lock1有诉求,则C(Lock1)≥pi(Task1),所以Task1无法锁住Lock0,该情况不成立,无法形成链
- 当Task1要占住Lock0时,若Task2尚未占住Lock1,
- 因为Task0对Lock0有诉求,说明C(Lock0)≥π(Task0),
- 因为Task1对Lock1有诉求,说明C(Lock1)≥π(Task1),
- 当Task2在申请Lock1,Task1已经占住Task0,此时Task2能获得Lock1,说明π(Task2)>C(Lock0)≥π(Task0),π(Task2)>π(Task0)说明链式调整不需要。
综上,PCP不用考虑链式调整。
缺点
PCP在绝大多数情况下都可以运行的很好了,缺点是:
- 只支持binary semaphore。缺少对多资源信号量的支持。
- 对动态优先级调度算法的实现过于复杂,要实时调整系统针对每个任务的priority ceiling。
- 虽然context switch已经叫PIP较为减少,但仍然有提升空间
SRP
SRP的产生可以克服这些PCP的缺点。
之所以叫stack based,因为它的诞生和嵌入式领域的stack sharing[1]有关。
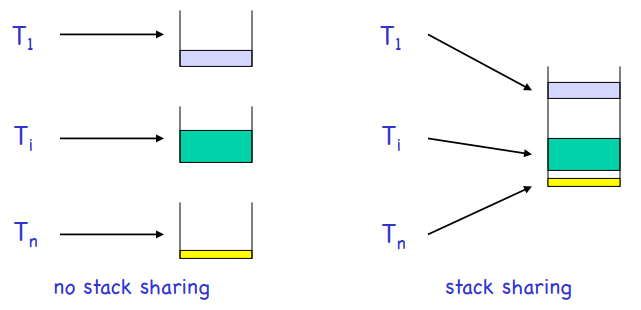
stack sharing用于节省内存。如果左边每个栈空间为10K,则总共需要30K。在栈空间不是很紧张的时候,采用stack sharing后,只需要总共10K的栈空间
stack sharing有一个特性,就是任务只能在栈顶的时候才能得到运行。当一个任务被另一个任务抢占后,意味着被抢占的任务要等到抢占者运行结束才有机会运行。
当采用stack sharing之后,stack也就变成了一种共享资源。
虽然SRP是因为stack sharing而产生,但即便在不是stack sharing的场合,也有很好的性能。
定义
preemption level
在[2][4]中都有提及如何定义preemption level,大意都是相同的。
[2]中提到
The reason for introducing preemption levels as distinct from priorities (p(J)) is to enable us to do static analysis of potential resource conflicts, even for some dynamic priority schemes such as EDF scheduling.
The only property of preemption levels on which these results do depend is the following condition (P1):
p(J)≤p(J′)⋃Arrival(J)≤Arrival(J′)⋃π(J)<π(J′)
[4]中提到
The general definition of preemption level used to prove all properties of the SRP requires that
if τa arrives after τb and τa has higher priority than τb, then τa must have a higher preemption level than τb
Under EDF scheduling, the previous condition is satisfied if preemption levels are ordered inversely with respect to the order of relative deadlines .
D(i)>D(j)⇒π(i)<π(j)
综上,总结如下:
- preemption level是一个抽象的数据,用来对资源竞争做静态分析。解决EDF框架中没有优先级数据的问题。
- preemption level在不同的调度框架下,实现方法可以不同,例如
- EDF,采用relative deadline的反比,即π(J)∝DJ1
- 其他调度框架,可以直接使用优先级数值
问题: 为什么在EDF下D(i)<D(j)能保证π(i)>π(j)?
证明:考虑下面两种情况:
- 若任务i先到,记作ti<tj,则ti+Di<tj+Dj,所以i的absolute deadline较小,i的优先级较高,且i先执行,j没有机会抢占i,所以π(i)>π(j)
- 若任务j先到,则考虑在SRP中,preemption只发生在任务开始时,所以j先到,j没有必要preempt,所以π(i)>π(j)
其他定义
-
priority:优先级,可能会动态调整,例如在一些动态优先级调度算法中,例如EDF
-
preemption level:相对优先级,preemption level是静态的,方便在动态优先级算法中,预测资源竞争。通常取任务的初始优先级。
-
ceiling:SRP的ceiling定义与PCP不一样。
⌈R⌉νR=max({0}⋃{π(J)∣νR<μR(J)})
其中:
- μR: maximum number of units of R that job J may need to hold at any one time.
- νR: the number of units of R that are currently available
- current ceiling: π=max{⌈Ri⌉νR∣i=1,…,m}
算法
因为preemption level是静态的,所以对ceiling的计算也是静态的,所以可以预先计算并写入一张表格。
引用原论文[2]中的例子
假如J1, J2, J3在生命周期中申请资源如下:

直观一点的资源申请图:
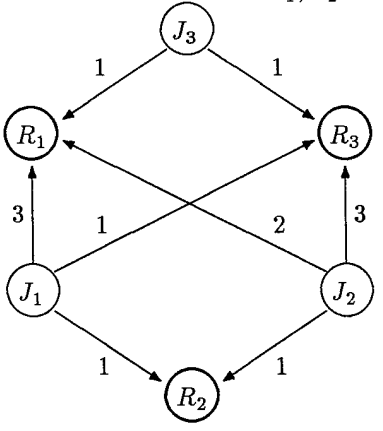
可以计算出⌈R⌉νR表格如下:
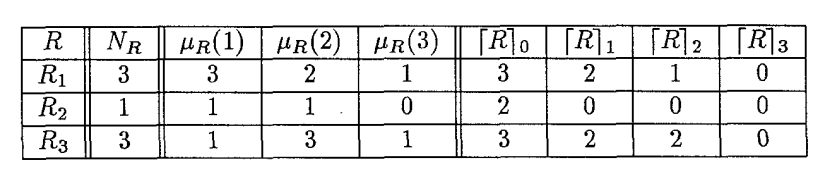
以⌈R2⌉0为例:
- νR=0
- ⌈R2⌉0=max({0}⋃{π(J)∣0<μR(J)})
- 若π(Ii)=p(Ji)=i , 则满足上式的最大的π(J)=2,如表所示。
- 当任务J ready时,计算此时的preemption level是否满足:π(J)>π,不满足则阻塞。
优点
- No job can be blocked after it starts. 没有block,所以没有额外的context switch。context switch只会发生在start execution和preemption。
- There can be n o transitive blocking or deadlock.
- If the oldest highest-priority job is blocked, it will become unblocked no later than the first instant that the currently executing job is not holding any non-preemptable resources
与PCP的异同
-
SRP与PCP相同的是,为了做统筹来得到全局最优解,二者都需要在系统初始化时决定每个资源的ceiling。
-
不同的是,两者评估线程重要程度的指标不同。PCP采用的是优先级,SRP采用的是抽象的preemption level。这导致两者的ceiling指标计算方法也不太一样。而且SRP因为采用的是抽象的preemption level,这在不同的调度策略下的含义也不一样,所以只能在同一种调度策略下参与统筹计算。
-
SRP对资源ceiling的计算方法,考虑了多资源,而PCP只能使用在二义锁的情况下。
-
因为SRP采用的是抽象的preemption level,所以可以很好的工作在类EDF调度策略下。而PCP如果要工作在EDF下,则比较困难。因为EDF的优先级由任务的绝对Deadline来决定,这与任务达到的时刻点有关系,如果要做PCP,就要知道线程的优先级,则要维护任务到达点信息,并计算优先级。
-
SRP因为他算法的优势,还带来了一些其他的优点,例如:
- 线程一旦开始,就不会因为资源而被block,这使得上下文切换次数可以减少到最少。
- 相比PCP,SRP更易于实现。
参考文献
[1] Bhuvan Middha, Matthew Simpson and Rajeev Barua, "MTSS: Multi Task Stack Sharing for Embedded Systems ", Department of Electrical & Computer Engineering University of Maryland College Park
[2] T.P. Baker, "A Stack-Based Resource Allocation Policy for Realtime Processes ", In Proceedings of the Real-Time Systems Symposium, pages 191–200, 1990
[3] Lui Sha; Ragunathan Rajkumar & John P. Lehoczky (September 1990). "Priority Inheritance Protocols: An Approach to Real-Time Synchronization". IEEE Transactions on Computers.
[4] The 2011 book Hard Real-Time Computing Systems: Predictable Scheduling Algorithms and Applications by Giorgio C. Buttazzo featured a dedicated section to reviewing SRP from Baker 1991 work.
[5] "Resource Access Protocols" slides from UPPSALA UNIVERSITET