- 人比工具重要,应先构建团队,再让团队基于需要配置环境
- 直到迫切需要并且意义重大时,才来编制文档。针对系统原理和结构方面的文档,应仅论述系统的高层结构和概括的设计原理
- 客户合同指导协作,而不是试图去规定项目范围的细节和固定成本下的进度。
- 为下两周做详细的计划,为下三个月做粗略的计划,再以后就做极为粗糙的计划。
- 客户作为团队成员
* 用户素材(user stories): UML Use Case图的Feature。参看UML Distilled笔记。
在XP中,我们和客户反复讨论,以获取对于需求细节的理解,但是不去捕获那些细节。我们更愿意客户在索引卡片上写下一些我们认可的词语,这些词语可以提醒我们记起这次交谈。基本上在和客户进行书写的同一刻,开发人员在该卡片上写下对应于卡片上需求的估算。估算时基于和客户进行交谈期间所得到的对于细节的理解进行的。
- 短交付周期,每2周迭代一次,并交付客户使用,每12周一次发布
- 每次交付都有客户针对feature的验收测试
- 结对编程
- 集体所有权,指不固定expert,凭兴趣决定想做的方向。
- 持续集成,类同第2点
- 可持续的开发速度。不允许加班,版本发布前一个礼拜例外
软件项目不是全速的短跑,它是马拉松长跑。
- 开放的工作空间
- 计划游戏
- 简单的设计
XP团队总是尽可能寻找能实现当前feature的最简单的设计 - 重构是持续进行的,每隔一个小时或半个小时就要去做的事情。
- 隐喻 (没看懂)
总结,这里极限编程其实强调的更多的是软件开发团队的运作方式,需要各方面达成一致,才能严格按照他的每一条去做。但是,即便在我们现在的环境下,不管是极限编程还是敏捷方法都不为人所知,没办法完全开展。但是里面的一些观点很有启发意义,仍然可以应用到我们日常的项目当中。比如第一点,要求开发人员实时同客户交流,并选定feature或及时修改开发方案。第二点,不断的交付。其实都可以马上运用上。
虽然书没看完,但是感觉这一部分是全书的核心,即敏捷开发的原则。
什么是敏捷设计?
敏捷设计是一个过程,一个持续的应用原则、模式以及实践来改进软件的结构和可读性的过程。
换而言之,就是不要随随便便打补丁,让程序能运行满足需求修改,而是应用各种方法使程序更具弹性。另一方面,又不为了修改而修改,不为了子虚乌有的弹性,花费额外的精力来达到想象中的弹性设计。
8-12章为我们介绍了面向对象设计的5原则:
- SRP: 单一职责原则
- OCP: 开放封闭原则
- LSP: Linskov替换原则
- DIP: 依赖倒置原则
- ISP: 接口隔离原则
逐一摘录如下:
在SRP中,我们把职责定义为“变化的原因”。如果你能想到多于一个的动机去改变一个类,那么这个类就具有多于一个的职责。
如果应用程序的变化方式总是导致这两个职责同时变化,那么就不必分离他们。
第一次的设计,我们常见的
NA
分离过职责以后
NA
这样的设计,如果两个接口变化频率非常不一致时,可以减少重新部署的范围。
- 对于扩展开放
- 对于修改关闭
怎么能做到呢?看下面的图:

抽象类和它们的客户的关系要比和实现它们的类的关系更密切。
意思是,Client与Client Interface的关系要比其与Server的关系更密切。
说到这里,这个原则其实已经很清晰了,但作者希望告诉我们更多。在《是的,我说谎了》那一节里,作者告诉我们,事实并不总像想象中那么美好。往往会有各种稀奇古怪的需求,导致原先的设计不能对该需求导致的变化封闭。作者给了我们忠告:
设计人员必须对于他设计的模块应该对哪种变化封闭做出选择。他必须先猜测出最优可能发生变化的种类,然后构造抽象来隔离那些变化。
这是很不容易做到的,要根据经验猜测哪些应用程序在生长历程中有可能的变化。
如何隔离变化:
- 在发现第一次变化时,进行抽象改造。
- 通过测试+快速迭代来刺激变化,尽快将变化的可能暴露出来。
本章还介绍了一种很实用的封闭变化的方法,使用“数据驱动”方法。其实就是表格驱动。将变化的部分总结固化到表格中。
开发人员应该仅仅对程序中呈现出频繁变化的那些部分做出抽象。拒绝不成熟的抽象和抽象本身一样重要
LSP - 子类型(的方法)必须能够替换掉它们的基类型(的方法)。
Linskov首次提出这个原则。
本章举的例子是正方形vs.矩形。以常理推论正方形IS-A矩形,所以正方形的类应当可以继承自矩形的类。但以替换原则看,在某些情况下正方形和矩形的行为并不一致。
void g (Rectangle& r)
{
r.SetWidth(5);
r.SetHeight(4);
assert(r.Area() == 20);
}
如果r传入的是正方形对象,则必然会出断言,所以这段代码不符合LSP。
OOD中IS-A关系是就行为方式而言。
可见,虽然代码是现实生活的抽象,但也不完全是。如何规避,或者说发现这种微妙的不同。作者给出一个方法就是基于契约的设计。通过设置前后置条件,来确定是否IS-A关系。
派生类中的例程
- 只能使用相等或更弱的前置条件来替换原始的前置条件,
- 只能使用相等或更强的后置条件来替换原始的后置条件。
- 可以在单元测试中指定前后置条件,来看是否满足IS-A的关系,如果不满足就要重新设计。
如何让代码做到LSP,方法就是摒弃曾经的抽象方法,通过在实践中,总结两个类行为一致的部分,并提取出公有的抽象父类。下图是例子


有可能引起违反LSP的两种情况:
- 派生类中方法定义为空函数,这种情况虽然没有违反LSP,但仍然会引起引用父类指针时的微妙区别。
- 从派生类抛出异常,明显违犯LSP,如果要遵循LSP,要么需要修改父类及使用预期,要么不抛异常。
总结:子类型的正确定义是“可替换性的”,这里的可替换性可以通过显式或者隐式的契约来定义。
这一条很有启示意义。以前从来没这么想过,但经作者一说,其实解答之前很多的疑惑。
无论如何高层模块都不应该依赖于低层模块。我们更希望能够重用的是高层的策略设置模块。
何为高层策略?
它是应用背后的抽象,是那些不随具体细节的改变而改变的真理

Lamp并不依赖于Button,而是Button依赖于Lamp提供出的接口ButtonServer。而这个interface也不局限于Button,其实只要有开关策略的具体类都可以实现这个接口。但是所有这些低层类统统依赖于这个高层提供的接口。而低层模块,如Button的修改并不会影响到Lamp。
有一天Lamp需要修改这个接口的时候,所有的类都会受到影响。这就是高层影响低层。但是Lamp是高层策略,是隐喻,并不会经常改变。
再看这个例子。
原始的算法如下


这个规则要解决的问题叫接口污染。
何为接口污染?看下面这个例子

接口隔离原则:不应该强迫客户依赖于它们不用的方法。
实现ISP的两个途径
这个不太好理解,而且这个方法按作者的说法也不是很好。

- 当Timed Door需要一个定时例程的时候,它先创建一个Door Timer Adapter对象,并以Timer Client的形式注册给Timer
- 当Timer计时到达时,Door Timer Adapter的Timeout会被调用
- 进而因为委托,会调用Timed Door的DoorTimeOut
这样做,就不需要Door来实现Timer接口,防止了接口污染。缺点是,每次需要定时程序的时候,都要创建一个Door Timer Adapter对象,浪费资源。
看上面的委托的例子,其实就很容易想到多重继承了。只要对TimedDoor采用多重继承就好了,既不影响Door的其他子类,又能使TimedDoor具有Timer和Door的双重功能。
采用多重继承后,上面例子的解决方案变成:

另外一个例子

这里有两点要注意:

应该这样写:

也不要这样写:

引申下来
void g(DepositUI&, TransferUI&);
void g(UI&);
哪种写法好?其实一目了然。肯定是第一种,虽然看起来有点啰嗦。作者告诉我们了:
无论是否有悖常理,多参数形式通常都应该优于单参数形式使用。
- 对客户分组。就像上面ATM的例子,对Transaction分类隔离。不同的客户要求的服务可能有重叠,如果重叠少就隔离,重叠多就抽取公共抽象类。
- 改变接口尽量通过新加接口来做,避免修改现有接口。因为你的子类可能正在用这个接口。
本书的第三~六部分,结合4个比较大型的例子,讲解了一系列设计模式。本部分涉及的模式有:
- COMMAND & ACTIVE OBJECT
- TEMPLATE METHOD & STRATEGY
- FACADE & MEDIATOR
- SINGLETON & MONOSTATE
- NULL OBJECT
其实每个模式,在看书的时候,结合作者给出的例子,很容易理解,也知道他在说什么,但是如果想要应用到实际的开发中,还是有一定难度的。作者在后文中,也给出一个例子,教读者如何通过抽象总结寻找适合自己的设计模式。但是不管怎么说,对每一个设计模式的特点和目的总要有一个清醒的认识,才能灵活的加以应用。
这两个模式都是基于对操作的封装。ACTIVE OBJECT模式基于COMMAND模式。下图就是COMMAND模式:

COMMAND模式可以分离操作发起者和操作本身。比如下面需要sensor驱动事件的模型。

若不采用COMMAND模式,sensor需要知道调用什么函数做什么操作。若采用COMMAND模式后,高层的掌握事件逻辑的模块,对sensor和事件进行绑定,之后sensor就可以对事件进行无差别的调用(command->do())。从而达到事件执行者和事件本身的解耦。
ACTIVE OBJECT基于COMMAND模式,有如下的简单结构:
public class ActiveObject{
Command itsCommands[];
public void run(){
for each command{
do();
}
}
public void addCommand(Command cmd) {
itsCommands.append(cmd);
}
}
该模式分离了任务的提交与任务的运行。按作者的说法,并参考网上其他的笔记,这个古老的设计模式往往会带来意想不到的好效果。
- 它可以模拟多线程的运行。实际上线程例程也可以是一个active object
- 我们可以在Command的do接口中决定下一步的操作,可以达到控制整个active object运行还是停止的效果。
在我看来,TEMPLATE METHOD并不能称为一种设计模式,只是把一些相同的流程,抽象成一个抽象基类,然后所有的派生类重用这个流程。但这往往沦为鸡肋,因为派生类总是在某个不确定的时间表现出不一样的行为,然后整个抽象的结构就被补丁打的面目全非。作者说,对TEMPLATE METHOD一定要慎之又慎,往往会出现模式滥用的情况。
TEMPLATE METHOD有一个很典型的例子,就是Bubble Sort。不管是对数字做冒泡,还是对字符做冒泡,还是对自定义对象做冒泡,其核心算法总是一样的。其不同在于
- 两个对象的比较操作
- 两个对象的交换操作
如此就可以很好的使用TEMPLATE METHOD了。把这两个操作作为接口抽象出来,冒泡排序的核心算法就是TEMPLATE METHOD了。
我觉得只有在这种超经典的环境下,才可以使用TEMPLATE METHOD。否则还是考虑其他模式吧。


当想要为一组具有复杂且全面的接口的对象提供一个简单且特定的接口时,可以使用队FACADE模式 。


这两个模式都是单例模式,一个关注结构(SINGLETON),一个关注行为(MONOSTATE)。
作者在本章开篇的时候说,
那些强制对象单一性的机制似乎有些多余。毕竟 ,在初始化应用程序时,完全可以只创建每个
对象的一个实例,然后使用该实例。事实上,这通常也是最好的方法。在没有急迫并且有意义的需要 时,应该避免使用这些机制。
那到底什么时候才是使用SINGLETON的正确时机呢?作者接着说了
我们也希望代码能够传达我们的意图。如果强制对象单一性的机制是轻量级的,那么传达意图带来的收益就会胜过实施这些机制的代价。
所以使用单例要符合两个元素:
- 机制轻量级,也就是逻辑要简单
- 需要传达只允许一个实例的意图
作者在本章结尾处指出:
如果希望透过派生去约束一个现存类,并且不介意它的所有调用者都必须要调用instance()方法来获取访问权,那么SINGLETON是最合适的。如果希望类的单一性本质对使用者透明,或者希望使用单一对象的多态派生对象,那么MONOSTATE是最适合的。
应用场景,例如:
- 工厂对 象(factories),用来创建系统中的其他对象。
- 管理器(managers)对象,负责管理某些其他对象并以合适的方式去控制它们。
因为这些类实例一旦产生超过一个,就会因为对象之间的同步问题,产生逻辑问题。
public class Singleton {
private static Singleton theInsLance = null;
private Singleton() {}
public static Singleton Instance()
{
if (theIristance == null)
theInstance = new Singleton();
return theInstance;
}
}
私有构造函数,通过static接口来做实例化,控制类实例只有一个。
下面的例子是Phoenix代码中最常见的单例模式。
class Child : public Parent
{
Child(){}
}
class Factory{
static Parent* Instance ()
{
static Child child;
return &child;
}
}
利用局部的static变量实现单例。不管用上面的哪种方式,其实例化过程都不是经典的面向对象方法,而需要调用者遵循约定,调用特殊的接口以创建类实例。其创建的实例确实都指向同一个真正的对象。
此模式与SINGLETON不同,MONOSTATE强调的是所有创建的对象具有相同的行为。
public class MonoState {
private static int itsX;
public void setX(int x) {
itsX = x;
}
public int getX(){
return itsX;
}
}
这里有一个约定:所有的类成员均为static,所有的方法均为非static
所有方法为非static的用意是,其接口均可继承到派生类中。所有成员变量是static,一方面保证所有类对象具有相同属性,另一方面也保证了MONOSTATE类的派生类都具有MONOSTATE特性。而实际上,所有派生类都共享同一个MONOSTATE的一部分。
这是一个很实用,但又总是很容易被忽略的模式。我们在写code的时候,下面的情况很常见:
Employee e = DB.getEmployee("Bob");
if (e != null && e.isTimeToPay(today))
e.pay();
先获得一个对象,在失败时返回null,然后根据返回的结果做下一步操作。使用NULL OBJECT以后的样子,可能是这样的:
Employee e = DB.getEmployee("Bob");
if (e.isTimeToPay(today))
e.pay();
public class NullEmployee {
public boolean isTimeToPay(Date data) {
return false;
}
}
import java.util.Date;
public interface Employee
{
public boolean isTimeToPay(Date payDate);
public void pay();
public static final Employee NULL = new Employee()
{
public boolean isTimeToPay(Date payDate)
{
return false;
}
public void pay()
{
}
};
}
使无效雇员类成为一个匿名内嵌类是一种确保该类只有单一实例的方法。实际上并不存在NullEmplyee类本身。其他任何人都无法创建NULL类实例。并且static final变量也保证了NULL的单例性。如果NULL不能做到单例的话,会引发歧义,导致不可预知的错误。
本部分只讲了一个模式(FACTORY),但放入了一个很有用的章节——关于包的设计原则。包是类的集合,当软件达到一定规模时,就需要考虑包的设计了。我觉得这值得反复阅读。我打算颠倒书上的顺序,先罗列FACTORY模式,再来看包设计规则。
这个模式,是我阅读这本书迄今为止(还有第四部分的三章未看),最有用的模式。他回答了我到底该在哪里传入多态绑定信息。
class Child1 : Parent{}
class Child2 : Parent{}
switch (info){
case A:
Parent* obj = new Child1();
break;
case B:
Parent* obj = new Child2();
break;
}
上面这一段不管是早绑定,迟绑定,总是要出现的。放在哪里?放在FACTORY里。
为什么要放到FACTORY里?换句话说:
作者说:
FACTORY模式允许我们只依赖于抽象接口就能创建出具体对象的实例。所 以 ,在正在进行的开发期间,如果具体类是髙度易变的,那么该模式是非常有用的。
严格按照DIP来讲,必须要对系统中所有的易变类使用工厂。针对这句话,作者又说:
我不是一开始就使用丁厂。只是在非常需要它们的情况下,我才把它们放入到系统中。例如,
- 如果有必要使用PROXY模式,那么就可能有必要使用工厂去创建持久化对象。
- 或者,在单元测试期间,如果遇 到必须要欺骗一个对象的创建者的情况时,那么我很可能会使用工厂。
但是我不是一开始就假设工厂是必要的。
一开始,不理解这句话,现在深深体会,工厂模式真的好,很容易被滥用。我现在就有滥用的倾向。
public interface IFactory{
public IObject makeObject();
}
public class Factory implements IFactory{
@Override
public IObject makeObject(){
return new Object();
}
}
public class Invoker{
public void func(){
IFactory factory = new Factory();
IObject = factory.makeObject();
}
}
Invoker类完全依赖于抽象的接口——工厂接口和Object接口,而不依赖于具体的类。在开发阶段,或者类结构不稳定阶段,我们可以任意修改makeObject接口的实现来生产我们需要的对象。
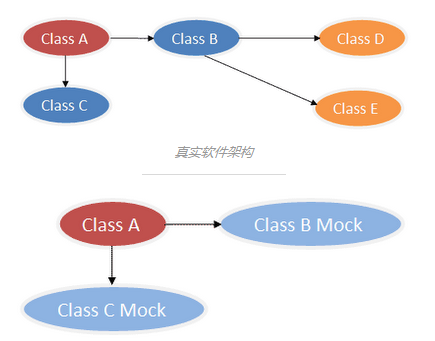
工厂模式在单元测试中也是很有用的。我们可以通过替换具体的工厂类来实现真实的类和mock类之间的切换。当然我们也可以用mockito来帮我们做这些事情。如果类庞大的mockito解决不了,一个工厂类可能会给我们提供意想不到的方便。
作者的例子:
在 某 些 情 况 下 , Payroll Test把 Database的引用传递给Payrol l是相当自然的,在另一些情况下,有可能PayrollTest必须设置一个全局变量保存对Database的引用。还有一些情况下Payroll可能完全期望自己来创建Database实例。在最后一种情况中,可以使用FACTORY模式,通过传给Payroll另外一个工厂对象,来欺骗Payroll创建出Database的测试版本。

一个包中的软件要么都是可重用的,要么都是不可重用的。我们不希望一个用户发现包中所包含的类中,一些是他所需要的,另一些对他却完全不适合。
我理解的意思就是,考虑问题要以包为最小粒度。类似类设计的SRP,单一职责原则。
CRP规定相互之间没有紧密联系的类不应该在同一个包中
这条原则规定了一个包小应该包介多个引起变化的原因。
如何避免”晨后综合症”
- 每周构建
- ADP——Acyclic Dependencies Principle无环依赖
有依赖环,则会影响到环上节点相关的所有节点,进而导致整个软件包的崩溃。所以切记,依赖关系分析很重要,绝不能有依赖环。

- 依赖倒置(DIP)

- 定义出共同依赖的包
20.5&20.6是本章的核心,在这两节中,作者阐述了如何定量地分析包的稳定性,并指导我们究竟改如何分布稳定类和非稳定类。这其中有一句话,让我印象颇为深刻:
并不是所有的类都适合作为稳定类。
这一章内容适合反复研读,我打算留做下一次再来做笔记。
这个模式是对COMMAND模式的扩展。为的是让多个对象的行为表现的像一个对象。例如:

这一章,作者给出了如何从最基本的coding方式,推演出如何套用合适的模式。其基本思想就是
不要过度设计,而是在不断的重构中,向某一种模式不断靠近,当其结构已经演化成某一种模式时,将所有的名称修改为该模式的术语,从而达到使用模式的目的
这实际是本章的精髓。
不过本章在阐述上述蜕化演进的过程的时候,以OBSERVER模式为例,也将这个模式的原理和使用方法讲的很清楚了。


拉模式适合简单的信息交互,Observer知道去Subject拉什么信息。
腿模式适合复杂信息交互,由Subject告诉Observer什么信息发生了变化。
这个模式很简单,很容易理解,看下面两幅图:

- 对Switch的继承,总是带上了Light信息,有可能导致修改
- 高层Switch依赖于Light
右边的图将Switch接口抽象出来,不管控制什么设备,只要定义了该接口就可以。
在这里,始终萦绕我的一个问题又出现了,就是何时实例化Light类?按照图25.2的逻辑,应该是Switch包含一个Light对象,在调用Switch的turnOn时,委托给Light的turnOn。
- 那么到25.3中,就应该是Switch持有一个Switchable的对象(可能是Light或者Fan等等)。那就可能是由某个工厂来产生这个对象给Switch。
- 还有一种可能就是,由客户逻辑来实现Switch和Switchable对象的绑定。例如
Switch.setSwitchable(Light)。在Switch中无差别的使用Switchable接口。
两个都是我的理解,不一定正确。以后若有机会与大师交流,可以当面提出这个问题。
在这一章作者还提出了一个很值得重视的问题(其实在前面的章节已经出现过),就是接口到底该和谁打包?看作者的阐述:
客户和接门之间的逻辑绑定关系要强于接口和它的派生类之间的逻辑绑定关系。它们之间的关系强到在没有Switchable的情况下就无法使用Switch;但是,在没有口Light的情况下却完全可以使用Switch。逻辑关系的强度和实体 关系的强度是不一致的。继承是一个比关联强得多的实体关系。
换句话说,我们应当按照逻辑关系的强弱来决定包的边界,即接口的客户应当接口的定义。继承关系是天然的,我们应当参考的是类之间的逻辑关系。
先看什么是ADAPTER模式
一般形式的ADAPTER:






Bridge模式在这本书上的内容没看懂,去参考设计模式圣经——《设计模式》。不愧为经典书,讲解的很清楚透彻。
书中给的例子是Window System,看下图:

- Window系统自身的演化
- 各个平台对Window系统的实现
如果他们都依赖于同一个继承关系,那就会出现类继承失控的现象。Bridge模式的出现就是为了解决这个问题。

这就是一个经典的Bridge模式。抽象的Window类和各平台的实现部分在各自的类层次结构中分别演化。Window与WindowImp之间的关系称为桥接。代码示例如下:
class Window
{
public:
virtual void DrawLine(const Point&, const Point&) = 0;
protected:
WindowImp* GetWindowImp(); //**********
private:
WindowImp* _imp;
View* _contents;
}
class WindowImp
{
public:
virtual void DrawLineImp(const Point&, const Point&) = 0;
}
class IconWindow : public Window
{
public:
virtual void DrawLine(const Point& a, const Point& b)
{
WindowImp* imp = GetWindowImp();
imp->DrawLineImp(a, b);
}
}
这里很有意思的是Window类的派生类,通过Window的protected接口来访问到对应的Imp接口。而GetWindowImp可能利用一个抽象工厂,来生成需要的对象。GetWindowImp可以在这个工厂中检测当前的平台来实例化对应的WindowImp类。
- 仅有一个Implementor的时候,没有必要创建一个抽象的Implementor类
- 实例化Imp类的方法有:
- 如果根抽象类知道所有的Implementor实现类,则可在其构造函数中根据需要来实例化一个Implementor类
- 首先选择一个默认的实现,然后根据需要改变这个实现
- 采用工厂模式来生产对应的Imp类对象
- 在C++中,可以使用多重继承结合两个抽象层次。但是这种办法依赖于静态继承。因此不可能用多重继承的方法来实现真正的Bridge模式。以Window系统为例,如果一个窗口类继承Window和WindowImp抽象类,但是他并没有获得XWindow的实现。
再回到《敏捷软件开发》这本书,看下图:

- ModemConnectionController定义了两个接口:原有的Modem和新的DedicatedModem。
- ModemConnectionController中所有的Imp接口均为Protected,只能被其子类使用。
- ModemConnectionController在适当的时机,实例化对应Modem的硬件实现,并将所有的Imp接口委托给这个实例。
用代码来阐述可能更直观:
public interface Modem {
public void Dial();
}
public interface DedicatedModem {
public void Send();
}
public abstract class ModemConnectionController implements Modem, DedicatedModem{
private ModemImplementation _imp;
protected ModemImplementation GetImp(int token){
switch (token) {
case 1:
return new Object();
}
}
protected void DialImpl(){
return GetImp(mToken).Dial(); // delegate
}
protected void SendImpl(){
return GetImp(mToken).Send(); // delegate
}
public void Dial() {}
public void Send() {}
}
public class DedModemController extends ModemConnectionController {
public void Dial(){ /* own version of Dial */ }
public void Send(){ return DialImpl(); }
}
public class DedUser {
void main(){
DedicatedModem dedModem = (DedicatedModem)new DedModemController;
dedModem.Dial();
dedModem.Send();
}
}
public class OldUser {
void main(){
Modem modem = (Modem)new HayesModem;
modem.Dial();
modem.Send();
}
}
因为*Impl函数的存在,DedModem可以演变成独立的类演化序列。
下图是一个典型的PROXY模式:

每个要被代理的对象都被分成3个部分:
- 一个接口,声明了客户要调用的所有方法
- 一个 类在不涉及数据库逻辑的情况下实现了接口中的方法
- 一个知晓数据库的代理

这个例子应该己经消除了所有关于使用代理是简单和优雅的错误认识。使用代理是有代价的。规范模式中所隐含的简单委托模型很少能够被优美地实现。相反,我们经常会取消对于繁琐的获取和设置方法的委托。
关于缓存
你可能会认为ProductProxy的实现是非常低效的。在每个访问方法中,它都会去使用数据库。如果它把ProductData条目进行缓存来避免访问数据库不是会更好一些吗?
虽然这个更改非常简单,但是促使我们这样做的惟一原因就是我们的恐惧。此时 ,还没有数据显示出这个程序具有性能问题。此 外,数据库引擎本身也会做一些缓存处理,所以建立自己的缓存会给我们带来什么好处并不明显。在做这些麻烦的工作前,我们应该等待,直到我们看到性能问题的迹象。
如果你担心性能可能是个问题,我建议你做一些试验去证明它确实是一个问题。当且仅当得到证实时,你才应该考虑如何去提速。
STAIRWAY TO HEAVEN使用了类形式(class form )的ADAPTER模式的一个变体.

- 核心部分就是上半部分的Product,PersistentObject和PersistentProduct,下面Assembly相关的部分是对Product部分的扩展
- PersistentProduct通过Product得到产品逻辑,通过PersistentObject获得障碍(数据库,网络等等)操作逻辑。
对比看PROXY的静态模型
在我们刚开始使用第三方API的时候,往往是这样的:





作者在本章最后还提到了几个操作第三方API的模式:
- Extension Object
- VISITOR
- Decorator
- Facade
作者最后的结论很有指导意义:
远在真正需要PROXY模式或者STAIRWAY TO HEAVEN模式前,就去预测对于它们的需要是非常有诱惑力的。但这几乎从来都不是一个好主意,特别是对于PROXY模 式。我建议在开始时先使用FACADE模式,然后在必要时进行重构。如果这样做的话,就会为自己节省时间并省去麻烦。
我在做微信IoT打印安卓端开发的时候,也是谨遵作者的教诲。FACADE模式前面有专门的章节介绍。这里再放一个本章的关于FACADE的截图。

VISITOR模式是一个很好的模式,他可以给现有的框架打补丁。作者给的例子是关于Modem的


- 一次次修改变成一次性操作。在Modem的接口中添加VISITOR接口,即上图中的accept。
- 当客户代码要为Unix配置的时候,调用对应实体Modem类的accept接口,该接口会调用Visitor->visit,并传入自身上下文
- 在visit里面就可以调用各个Modem暴露出来的public方法了,注意不是Modem接口哦,是具体类的public方法
- 如果我们需要其他的访问代码,我们可以加一个类,并定义ModemVisitor接口就可以了。这个类可以做任意想做的事情,不局限于ModemConfigurator
这里还学到一个java的小知识:
我们知道有private, protected, public,如果不写默认是什么?
- C++里默认是private
- Java里不写的话,表示包级访问权限,意即只有同一个包里的代码可以调用。如果软件只有一个包,就等同于public。因为Java中没有friend关键字,这一功能可以起到一部分friend的作用。其实也就是Java的作者认为,包内的类都是友元。
acyclic —— 无环的,这里指没有依赖环。
作者在本节一开始的时候就介绍了为什么要在VISITOR的基础上引入ACYCLIC变体。不过我想了好久,也没太理解。暂且罗列如下:
请注意,被访问 (Modem)层次结构的基类依赖于访问者层次结构(ModemVisitor)的基类。同样请注意,访问者层次结构的基类中对于被访问层次结构中的每个派生类都有一个对应函数。因此,就有一个依赖环把所有被访问的派生类(所有的调制解调器)绑定在一 起。这样,就很难实现对访问者结构的增量编译,并且也很难向被访问层次结构中增加新的派生类。
如果程序中要更改的层次结构不需要经常地增加新的派生类,那么VISITOR模式工作的很好。如果我们很可能只需要Hayes、Zoom以及Ernie,或者很少会去增加新的Modem派生类,那么VISITOR模式将会非常合适。
另一方面,如果被访问层次结构非常不稳定,经常需要创建许多新的派生类,那么每当向被访问 层次结构中增加一个新的派生类时,就必须要更改并且重新编译VISITOR基类(也就是ModemVisitor)以及它的所有派生类。在C++中,情况甚至更糟。每当增加任何一个新的派生类时,整个被访问层次结构就必须要被重新编译、重新部署。
谈一下我的理解。这可能和Java的编译过程有关系。先把VISITOR中的类图拷过来:
- ModemVisitor要添加一个接口
- 因为依赖关系Modem要重新编译
- 定义了Modem接口的类都要重新编译
关于C++的描述:
在C++中,情况甚至更糟。每当增加任何一个新的派生类时,整个被访问层次结构就必须要被重新编译、重新部署。
在C++中,interface一般会是一个头文件,被所有实体类包含,一个头文件改动,则该类图中所有的类都会需要重新编译。
*这里只强调编译,链接总是都要重新做的。
理解了为何要有ACYCLIC变体以后,再看什么是ACYCLIC VISITOR:

- 针对每个Modem类都有一个Visitor接口,注意是接口
- UnixModemConfigurator定义了所有Modem的Visitor接口,并且也定义了那个空的接口ModemVisitor。这样Modem就可以通过ModemVisitor接口访问到UnixModemConfigurator了。
- 因为ModemVisitor是一个空接口(退化的),所以不管添加多少Modem实体类,ModemVisitor都不用修改,那Modem接口不用跟着重新编译。只有新增加的Modem实体类和UnixModemConfigurator会被编译。
ACYCLIC VISITOR很巧妙地解决了依赖环的问题。他的缺点是,在实体Modem类中,需要对传入的ModemVisitor接口进行强制类型转化,变成对应的Visitor接口。这会对执行效率引入不确定性。
更糟糕的是,转型花费的时间依赖于被访问层次结构的宽度和深度,所以很难进行测定。由于转型需要花费大量的执行时间,并且这些时间是小可预测的,所以ACYCLIC VISITOR模式不适用于严格的实时系统。
对于那些被访问的层次结构不稳定,并且增暈编译比较重要的系统来说,该模式是一个不错的选择 。

一般来说,如果一个应用程序中存在有需要以多种不同方式进行解释的数据结构,就可以使用VISITOR模式。
其实就是实现数据与视图的分离,类似MVC的概念。
最早接触decorator是在python的@语法,参看这篇笔记理解Python中的装饰器。那时候还不懂什么设计模式。
最近在做Android程序的JUnit代码里也有装饰器。可见其应用之广。
现在就可以看一下正规的Decorator怎么做?

Decorator的主要作用就是消除重复代码。
如果有多个Decorator,要消除委托代码的重复,可以用下面的类图:


- Part用HashMap管理PartExtension
- PartExtension是一个退化的接口(即无方法的接口),所以使用的时候会要做强制类型转换
- PartPiece和Assembly在构造的时候添加对应的extension object,则在需要的时候可以get出来
- PartPiece和Assembly在extension构造的时候,把自己传给该extension,则实现了Visit功能。
Visitor可以实现不去修改类层次结构的情况下,向其中添加新功能。但是所有的访问功能都在一个类当中,如我们例子是在UnixModemConfigurator中,而且对每个Modem类只有一个visit函数。
当我们需要隔离对各个类的访问进行隔离,或者需要对一个类有不同的访问方式,VISITOR模式就做不到了。
于是有升级版的VISITOR,也就是EXTENSION OBJECT。每一个类可以有任意多的访问方式,且每个类之间的访问和不同访问方式之间都是隔离的。例如本例中,有两个被访问的类(PartPiece & Assembly),有两种访问方式(XML & CSV)。所以总共有4个extension object。
*作者时时在提醒我们
- 所有代码是从测试用例演化而来,所有代码都刚好让测试通过,不多也不少。(这个节奏很难把握,还在学习中)
- 不要为了模式而模式,而是先有代码,要消除重复,重构时才慢慢演化成适当的模式。而模式并不一定是标准的,有可能是经过修改而适合使用的
看看最一开始的代码可能是这样的
public PartExtension getExtension(String extensionType)
{
if (extensionType.equals(""XML"))
return new XMLPiecePartExtension(this);
else if (extensionType.equals("CSV"))
return new XMLAssemblyExetnsion(this);
return new BadPartExtertsion();
}
STATE模式这就是有限状态机。其应用相当广泛——UI,数据接口(例如control panel的命令)等等。下面是十字转门的状态迁移图。

看看真正的STATE模式是怎么实现的:

- TurstyleState的派生类,代表状态本身
- Turnstyle代表了整个系统,其包含了所有状态对象,也包含了所有状态迁移时产生的动作
- TurstyleState的派生类负责调用Turnstyle的状态迁移接口,和迁移动作。
STATE模式彻底地分离了状态机的逻辑和动作。动作是在Context类中实现的,而逻辑则是分布在STATE类的派生类中。这就使得二者可以非常容易地独立变化、互不影响。
在STATE模式中,派生类持有回指向上下文类的引用。派生类的主要功能是使用这个引 用选择并调用上下文类中的方法。在STRATEGY模式中,不存在这样的限制以及意图。STRATEGY的派生类不必持有指向上下文类的引用,并且也不需要去调用上下文类的方法。所以,所有的STATE模式实例同样也是STRATEGY模式实例,但是并非所有的STRATEGY模式实例都是STATE模式实例

这是一个代码生成器。在前面介绍STATE模式的时候,会发现,其实最核心的部分就是状态迁移表。这样一章表格其实包含了整个有限状态机系统所有的逻辑。而SMC就是根据这样一张类似的表格来生成STATE模式中的各个类。

 - Linear & Logistic Regression/1491028424509.png)
 - Linear & Logistic Regression/SVG7d23ac9b0599a1fe6ce93afb5acdb6c0)
 - Linear & Logistic Regression/SVGe9c66918863dbfb4732bb0d990d7e512)
 - Linear & Logistic Regression/SVGadfa7edb34cfa9178eb8de77c5c3da6b)
 - Linear & Logistic Regression/SVGa2e9495bfc83fe763885a95044e1d45f)
 - Linear & Logistic Regression/SVGcebf52d0718dce59146d554a10fc1033)
- Learning rate.
) may not decrease on every iteration; may not converge.
 - Linear & Logistic Regression/SVG28c30732fe3fef9c54f59e001a9b54ec)
is the average of all the values for feature (i)
is the range of values (max - min)
 - Linear & Logistic Regression/SVGb100946ff715835a9459d3585b8c965d)
 - Linear & Logistic Regression/SVGb27f34569e87884e097e71391e6ca12f)
会不可逆,导致没有解
 - Linear & Logistic Regression/SVGd1a694857d9539d6607e89671d43b048)
 - Linear & Logistic Regression/SVGe33136bdc60e1298d6e84de170630909)
 - Linear & Logistic Regression/SVG9b460439e20c54f261504f5da59a746a)
 - Linear & Logistic Regression/1491033397652.png)
 - Linear & Logistic Regression/SVG88b1d566aa187c2b8edaaa733182c33d)
 - Linear & Logistic Regression/SVG93ff7b61ca29f13fdf4c92ccc47ee6da)
 - Linear & Logistic Regression/SVG75fca90d33cb4a375540207f6f2a7be0)
 - Linear & Logistic Regression/SVG73eab47a2d92d756f0c7068704f8757e)
 - Linear & Logistic Regression/SVGd52110682affea90d031dfc31bc39fbf)
 - Linear & Logistic Regression/SVGfaf5dc80308d8f1dd0c9b9ff36e123d9)
 - Linear & Logistic Regression/SVG6af02d365362292dcf60cbad81a56b69)
 - Linear & Logistic Regression/SVG2585329387d19621abb8e899dc65d45a)
 - Linear & Logistic Regression/SVG01f2b314c5db3826fb1eb2c0695aec72)
 - Linear & Logistic Regression/SVG5cf1646f441aa186c9f8eb1eb64b13f8)
 - Linear & Logistic Regression/SVG85456d63b56d16b7345ac846cc85ecf2)
 - Linear & Logistic Regression/SVGdcd056880207c58c97844ff015771e2d)
 - Linear & Logistic Regression/SVGf6970f60bdac10b142d1d13d4b2c346b)
 - Linear & Logistic Regression/SVGc4b17cdb4d55d3e56b08936c7ec923af)
 - Linear & Logistic Regression/SVG33a12c1d855f9f8f289dcef9d076110f)
 - Linear & Logistic Regression/SVGc49237343ca20e996bdd8b1b0596221f)
 - Linear & Logistic Regression/SVG9411849528295073b7b752b252831838) means to explicitly exclude the bias term
means to explicitly exclude the bias term  - Linear & Logistic Regression/SVG1a3151e36f9f52b61f5bf76c08bdae2b)
 - Linear & Logistic Regression/SVGedcbf8dd6dd9743cceeee21183bbc3b6)


/1470561176490.png)
/1469631172614.png)
/1470056081607.png)
/1470057983821.png)
/1470058049870.png)
/1470058186471.png)
/1470058339705.png)
/1470058566116.png)
/1470058643590.png)
/1469861506321.png)
/1469861910016.png)
/1469862941546.png)
/1469863153757.png)
/1469863497950.png)
/1469863936140.png)
/1469864217899.png)
/1469864349862.png)
/1469867539007.png)
/1469867666058.png)