1)换出
当内核在分配内存时,调用__alloc_pages,如果没有空闲页,内核会启动页面交换机制,也就是try_to_free_pages。代码如下:
1293 page = get_page_from_freelist(gfp_mask, order,
1294 zonelist, ALLOC_NO_WATERMARKS);
1295 if (page)
1296 goto got_pg;
1306 if (!w ait)
1307 goto nopage;
1316
1317 did_some_progress = try_to_free_pages(zonelist->zones, gfp_mask);
可以看到,如果分配者允许等待,则会开始回收页面。再往下的调用关系如下:
try_to_free_pages->shrink_zones->shrink_zone->shrink_inactive_list->add_to_swap->pageout->(swapper_space.a_ops->writepage)
最终调用块设备接口,将page写到磁盘交换分区的swap file上。
2)换入
当引发缺页异常时,内核调用handle_pte_fault,当检测到
!pte_present(entry) <=> (pte_val(pte) & L_PTE_PRESENT == 0)
此时会调用do_swap_page->read_swap_cache_async->swap_readpage来读入换出的页数据到新的一页,原先的页面会释放成hot page到伙伴系统。
2.swap的工作原理
swap就是交换,每次需要交换哪些,和linux的页回收机制也就是著名的LRU算法,有些相似。彼是决定要回收哪些。之前我们也提到过LRU这个名词。现在可以知道他到底是一个什么样的算法了。LRU = Least Recently Used,可以参考
LRU算法。
对于交换算法,我们对页面的新旧程度不需要弄的那么清楚,我们只需要知道有两个list:active_list & inactive_list。每次try_to_free_pages在交换时,将active page放一部分到inactive list,再将inactive page释放一部分到磁盘上。其核心函数就是上面提到的shrink_zone。
1)首先来看try_to_free_pages
for (priority = DEF_PRIORITY; priority >= 0; priority--) {
……
nr_reclaimed += shrink_zones(priority, zones, &sc);
shrink_slab(sc.nr_scanned, gfp_mask, lru_pages);
……
}
这里有一个priority的机制。这里其实并没有什么优先级机制,只是每次尽量少的扫描页面,以保证速率。到shrink_zone里面有:
zone->nr_scan_active +=
(zone_page_state(zone, NR_ACTIVE) >> priority) + 1;
这一段我一度看了好久,其实不要考虑的那么死。他只是一个一步步增加扫描页面的数量的方法。当priority = 12~1的时候,扫描数量每次增加zone->nr_active/(2^priority)个页面。如果到priority =1的时候,nr_scan_active仍然没达到sc->swap_cluster_max(32)的话,即scan的总数的理论值为zone->nr_active*(1-1/(2^12)),则priority=0,此时scan总数将超过zone->nr_active的总数。那是不是就有问题了呢?当然不是,因为后面再做页面转移的时候,检测标准是list_empty,不会操作超过列表范围的页面的。
2)shrink_zone
/* 根据priority来决定扫描页面的数量,inactive的数量采用同样的方式获得
* 至少要保证sc->swap_cluster_max个页面,即32个页面
*/
918 zone->nr_scan_active +=
919 (zone_page_state(zone, NR_ACTIVE) >> priority) + 1;
920 nr_active = zone->nr_scan_active;
921 if (nr_active >= sc->swap_cluster_max)
922 zone->nr_scan_active = 0;
923 else
924 nr_active = 0;
925
……
933 // nr_active: 从active转到inactive列表上的页面数
// nr_inactive: 从inactive列表换出到磁盘的页面数
934 while (nr_active || nr_inactive) {
935 if (nr_active) {
936 nr_to_scan = min(nr_active,
937 (unsigned long)sc->swap_cluster_max);
938 nr_active -= nr_to_scan;
939 shrink_active_list(nr_to_scan, zone, sc, priority);
940 }
941
942 if (nr_inactive) {
943 nr_to_scan = min(nr_inactive,
944 (unsigned long)sc->swap_cluster_max);
945 nr_inactive -= nr_to_scan;
946 nr_reclaimed += shrink_inactive_list(nr_to_scan, zone,
947 sc);
948 }
949 }
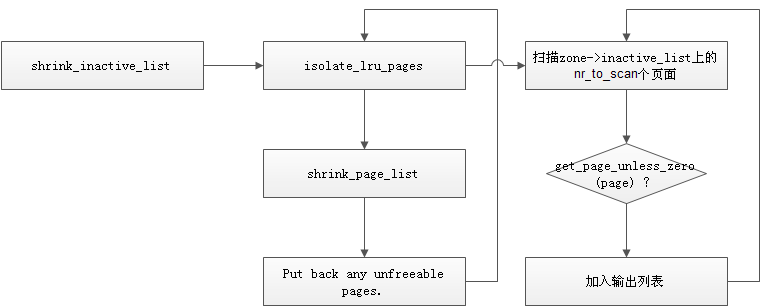
3)shrink_inactive_list
经过上面的分析,其实已经可以看出,shrink_inactive_list要做的工作就是,扫描传入的nr_to_scan页面,再将合适的页面换出到磁盘,并返回换出的页面数。其流程如下:
是不是很简单,没错,就是这么简单。isolate_lru_pages负责扫描页面的struct page结构,根据其flags来决定是否可以换出,可以换出的放到输出列表上,以备shrink_page_list来做真正的换出。
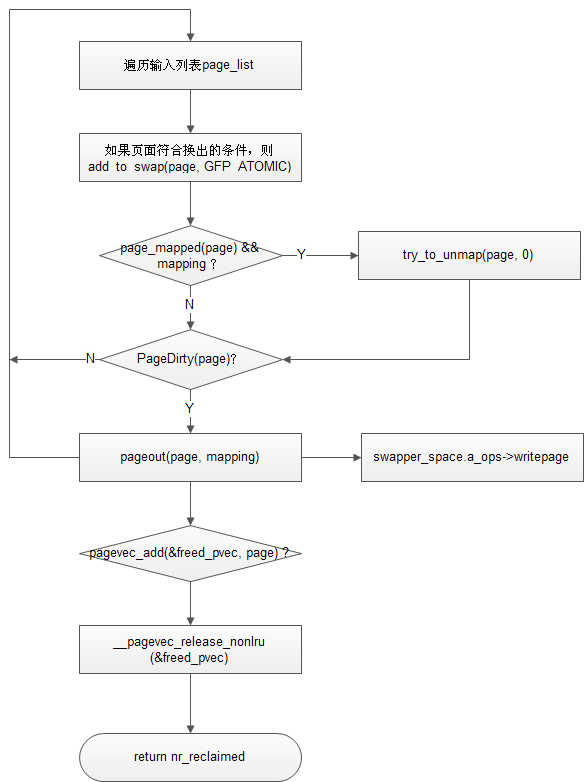
4)shrink_page_list
其主线如下:
经过一系列的判断后,将页面换出,并且用__pagevec_release_nonlru(&freed_pvec)将页面释放回buddy system,注意在创建freed_pvec时,指定了页面的属性为cold。整个算法的精髓,在于哪些inactive的页面不可以换出。
先看,shrink_page_list中有几个标号
keep:直接将页面add回page_list
keep_locked:指该页面已经被lock了,需要先解锁再进入keep标号
activate_locked:将页面激活,再放回page_list,这个在后续,该页面会被放入active list
free_it:这个是正常流程,页面会被释放,然后进入扫描下一个页面
所以代码中,凡是经过判断后,要调转到以上前三个标号的地方,那些页面都是不会被换出释放的。具体来说,有以下这些情况:
a. !sc->may_swap && page_mapped(page)
b. PageWriteback(page)
c. PageDirty(page) && page_referenced(page, 1)
d. PageDirty(page) && !may_enter_fs
e. PageDirty(page) && !sc->may_writepage
(1)swapper_space:
如果page->mapping等于0,说明该页属于交换告诉缓存swap cache
(2)anon_vma:
如果page->mapping不等于0,但第0位为0,说明该页为匿名也,此时mapping指向一个struct anon_vma结构变量;
(3)address_space:
如果page->mapping不等于0,但第0位不为0,则mapping指向一个struct address_space地址空间结构变量;
5)swap cache
上面简述了linux页缓冲交换机制的工作原理,最后回到swap cache这一基本结构上来。gorman的书里面讲得很清楚了。下面做一些笔记。
为什么要有swap cache这个东西?
因为A significant number of the pages referenced by a process early in its life may only be used for initialization and then never used again. It is better to swap out those pages and create more disk
buffers than leave them resident and unused.
swap cache vs. page cache
The swap cache is purely conceptual because it is simply a specialization of the page cache.
1. in the swap cache rather than the page cache is that pages in the swap cache always use swapper space as their address space in page→mapping.
2. pages are added to the swap cache with add_to_swap_cache(),shown in Figure 11.3, instead of add_to_page_cache().
所有的swap file信息都保存在这个数组中
static struct swap_info_struct swap_info[MAX_SWAPFILES];
可见swap file最多可以有MAX_SWAPFILES个,也就是32个。
64 struct swap_info_struct {
65 unsigned int flags;
66 kdev_t swap_device;
67 spinlock_t sdev_lock;
68 struct dentry * swap_file;
69 struct vfsmount *swap_vfsmnt;
70 unsigned short * swap_map;
71 unsigned int lowest_bit;
72 unsigned int highest_bit;
73 unsigned int cluster_next;
74 unsigned int cluster_nr;
75 int prio;
76 int pages;
77 unsigned long max;
78 int next;
79 };
swap_info是一个数组,也是一个虚拟链表,每个成员用next指向了下一个链表成员的索引号。这个链表同时用另一个变量描述。这里指明了这个链表的头在哪里,其表尾成员的next = -1。
153 struct swap_list_t {
154 int head; /* head of priority-ordered swapfile list */
155 int next; /* swapfile to be used next */
156 };
swap area由swap_info_struct描述,并且可以通过命令动态的增加。每一个swap area指向一个swap file,该file被分割成若干个page size的slot,第0个slot被用来存储swap_header,如下:
25 union swap_header {
26 struct
27 {
28 char reserved[PAGE_SIZE - 10];
29 char magic[10];
30 } magic;
31 struct
32 {
33 char bootbits[1024];
34 unsigned int version;
35 unsigned int last_page;
36 unsigned int nr_badpages;
37 unsigned int padding[125];
38 unsigned int badpages[1];
39 } info;
40 };
添加padding是为了能和磁盘的cluster对齐,badpages数组限制了一个swap area的页数,其尺寸由下面的公式得到。每个成员指向了一个page结构体。
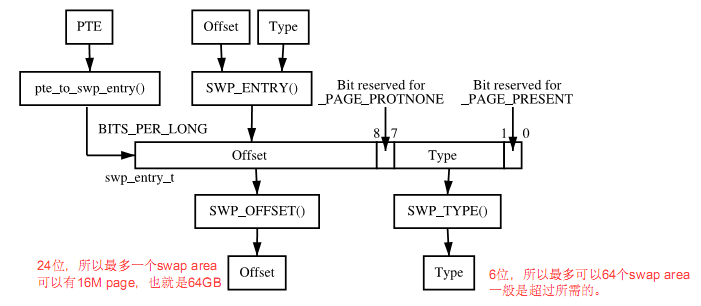
swap cache最核心的部分,是一个叫做swp_entry_t的结构,其实他就是一个unsigned long。当页面被换出时,其原先的页表项pte被用于存储这个值。通过这个swp_entry_t,我们可以定位到该页数据被写到哪个swap area的哪个位置。其组成如下图所示:
Type指引了哪个swap area,offset指引了该页在swap_map数组中的位置,也可以通过改offset算得swap file中的sector位置。具体可以参考下面的函数
(swapper_space.a_ops->swap_writepage) -> get_swap_bio -> map_swap_page
938 for ( ; ; ) {
939 struct list_head *lh;
940 /*一直循环到offset落在该sector中*/
941 if (se->start_page <= offset &&
942 offset < (se->start_page + se->nr_pages)) {
943 return se->start_block + (offset - se->start_page);
944 }
945 lh = se->list.next;
946 if (lh == &sis->extent_list)
947 lh = lh->next;
948 se = list_entry(lh, struct swap_extent, list);
949 sis->curr_swap_extent = se;
951 }
那么这个swap_entry_t是怎么来的?其实也很简单,就是在swap_map数组中挨个找,first fit法。当然具体还有些技巧,其实在搜索时,是按照cluster的范围寻找,也就是循环直到找到一个空的cluster(256个等于0的swap_map成员)为止,目的是to have pages swapped out at the same time close together on the premise that pages swapped out together are related 。
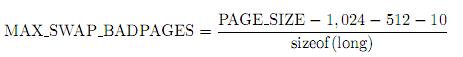
—— kmalloc/1537085026613)
—— kmem_cache_create/1499486796586)
—— kmem_cache_create/1499486796244)
—— kmem_cache_create/1499486796738)
—— kmem_cache_create/1499486796416)
—— kmem_cache_create/1537085030569)
—— kmem_cache_create/1537085030564)
—— kmem_cache_create/1537085030571)
—— kmem_cache_create/1537085030566)
—— array_cache/1499486792698)
—— array_cache/1499486792860)
—— array_cache/1537085030103)
—— array_cache/1537085030106)
 —— 初始化/1499486800011)
 —— 初始化/1499486799339)
 —— 初始化/1499486799878)
 —— 初始化/1499486799641)
 —— 初始化/1499486799475)
 —— 初始化/1537085031252)
 —— 初始化/1537085031241)
 —— 初始化/1537085031250)
 —— 初始化/1537085031247)
 —— 初始化/1537085031245)