migrate type——buddy system的好搭档
Linux一共定义5中migrate type,如下:
#define MIGRATE_UNMOVABLE 0#define MIGRATE_RECLAIMABLE 1
#define MIGRATE_MOVABLE 2 /* 未见有使用该标志位的代码*/
#define MIGRATE_PCPTYPES 3 /* the number of types on the pcp lists */
#define MIGRATE_RESERVE 3
#define MIGRATE_ISOLATE 4 /* can't allocate from here */
#define MIGRATE_TYPES 5
为什么要定义migrate type,可以参考linux内核对伙伴系统的改进--migrate_type。简要来说就是Linux将可移动或不可移动的内存分开分配,以便最大程度的减少碎片,提升分配大块内存的能力。基于这种思路,可见上述5种migrate type最重要的就是MIGRATE_UNMOVABLE,MIGRATE_MOVABLE。另一个重要的type就是MIGRATE_RESERVE,这表示page被reserve,不接受buddy system管理,可参见函数setup_zone_migrate_reserve。在启动时,会依据water mark min来reserve一些page做备用。
这三个type是用到最多的三种,下面的fallback机制也用到了
static int fallbacks[MIGRATE_TYPES][MIGRATE_TYPES-1] = {[MIGRATE_UNMOVABLE] = { MIGRATE_RECLAIMABLE, MIGRATE_MOVABLE, MIGRATE_RESERVE },[MIGRATE_RECLAIMABLE] = { MIGRATE_UNMOVABLE, MIGRATE_MOVABLE, MIGRATE_RESERVE },[MIGRATE_MOVABLE] = { MIGRATE_RECLAIMABLE, MIGRATE_UNMOVABLE, MIGRATE_RESERVE },[MIGRATE_RESERVE] = { MIGRATE_RESERVE, MIGRATE_RESERVE, MIGRATE_RESERVE }, /* Never used */};migrate type在memmap_init中初始化为MIGRATE_MOVABLE,如下:
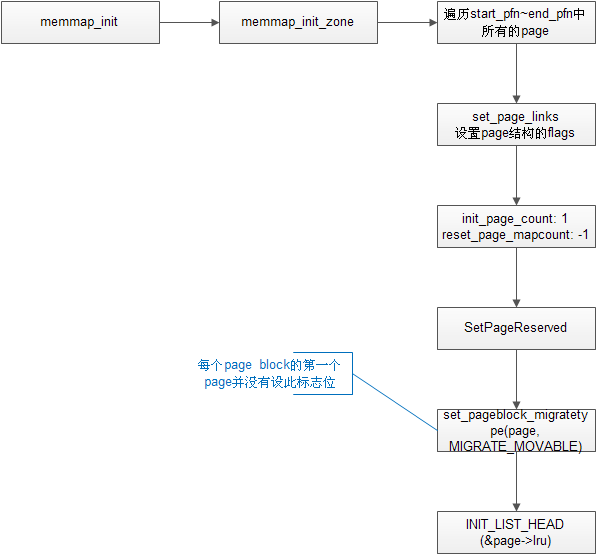
void __meminit memmap_init_zone(unsigned long size, int nid, unsigned long zone,
unsigned long start_pfn, enum memmap_context context)
{
struct page *page;
unsigned long end_pfn = start_pfn + size;
unsigned long pfn;
struct zone *z;
if (highest_memmap_pfn < end_pfn - 1)
highest_memmap_pfn = end_pfn - 1;
z = &NODE_DATA(nid)->node_zones[zone];
for (pfn = start_pfn; pfn < end_pfn; pfn++) {
……
page = pfn_to_page(pfn);
……
SetPageReserved(page);
/*
* Mark the block movable so that blocks are reserved for
* movable at startup. This will force kernel allocations
* to reserve their blocks rather than leaking throughout
* the address space during boot when many long-lived
* kernel allocations are made. Later some blocks near
* the start are marked MIGRATE_RESERVE by
* setup_zone_migrate_reserve()
*
* bitmap is created for zone's valid pfn range. but memmap
* can be created for invalid pages (for alignment)
* check here not to call set_pageblock_migratetype() against
* pfn out of zone.
*/
if ((z->zone_start_pfn <= pfn)
&& (pfn < z->zone_start_pfn + z->spanned_pages)
&& !(pfn & (pageblock_nr_pages - 1)))
set_pageblock_migratetype(page, MIGRATE_MOVABLE);
INIT_LIST_HEAD(&page->lru);
……
}
}
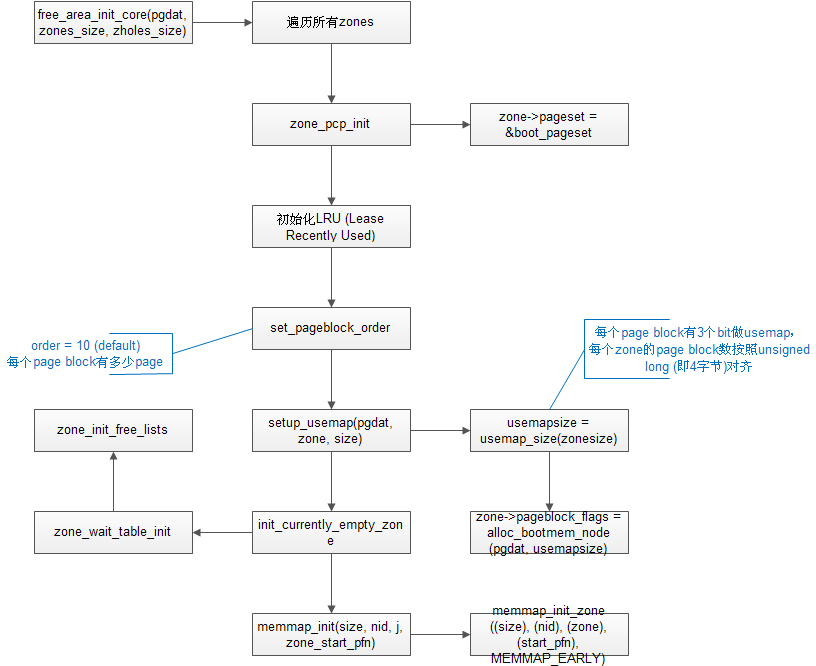
上面的函数,遍历memmap数组,也就是该zone所有页面的page结构体,
1)首先设置page->flags的PG_reserved位,意思是不受内存管理系统控制。没错,此时仍在bootmem控制下,之后再__free_pages_bootmem时,会清除该位,将其纳入buddy系统。
2)之后set_pageblock_migratetype将所有page的migrate type设为MIGRATE_MOVABLE。之前提到的按照water mark min来reserve一些页面,顺序上在这个函数的后面才会被调用。
3)再看一下migrate type的初始化函数,set_pageblock_migratetype -> set_pageblock_flags_group
void set_pageblock_flags_group(struct page *page, unsigned long flags,int start_bitidx, int end_bitidx){struct zone *zone;unsigned long *bitmap;unsigned long pfn, bitidx;unsigned long value = 1;zone = page_zone(page);pfn = page_to_pfn(page);bitmap = get_pageblock_bitmap(zone, pfn);bitidx = pfn_to_bitidx(zone, pfn);for (; start_bitidx <= end_bitidx; start_bitidx++, value <<= 1)if (flags & value)__set_bit(bitidx + start_bitidx, bitmap);else__clear_bit(bitidx + start_bitidx, bitmap);没有想象的那么简单吧,其中有一个bitmap,他是什么呢?如下:}
所谓的bitmap就是zone->pageblock_flags。每个zone被分割成若干个pageblock,每个pageblock分配3位来表示migrate type。pageblock其实就是freearea中order最大的一块内存,从下面的代码可以看出来:static unsigned long __init usemap_size(unsigned long zonesize){unsigned long usemapsize;usemapsize = roundup(zonesize, pageblock_nr_pages);usemapsize = usemapsize >> pageblock_order;usemapsize *= NR_PAGEBLOCK_BITS;usemapsize = roundup(usemapsize, 8 * sizeof(unsigned long));return usemapsize / 8;}static void __init setup_usemap(struct pglist_data *pgdat,struct zone *zone, unsigned long zonesize){unsigned long usemapsize = usemap_size(zonesize);zone->pageblock_flags = NULL;if (usemapsize)zone->pageblock_flags = alloc_bootmem_node(pgdat, usemapsize);}
free_area_init_core -> set_pageblock_order(pageblock_default_order())
static inline int pageblock_default_order(void){if (HPAGE_SHIFT > PAGE_SHIFT)return HUGETLB_PAGE_ORDER;return MAX_ORDER-1;}
在使用的时候,用get_pageblock_migratetype(page)来获得本page的migrate type。因为只要没有做migrate type的迁移,每个page的migrate type总是和他所在的pageblock是一致的。migrate type只会在fallback机制中改变。也就是分配内存,在本migrate type中无内存可分配,就要去备用的migrate type列表中找最大块内存,迁移过来,再不济还有reserved的页面。
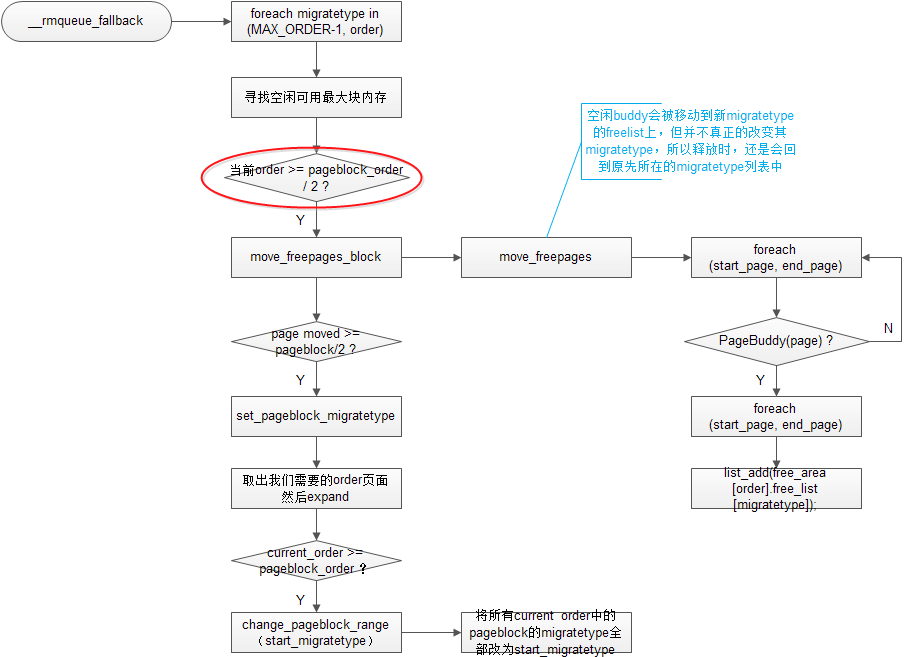
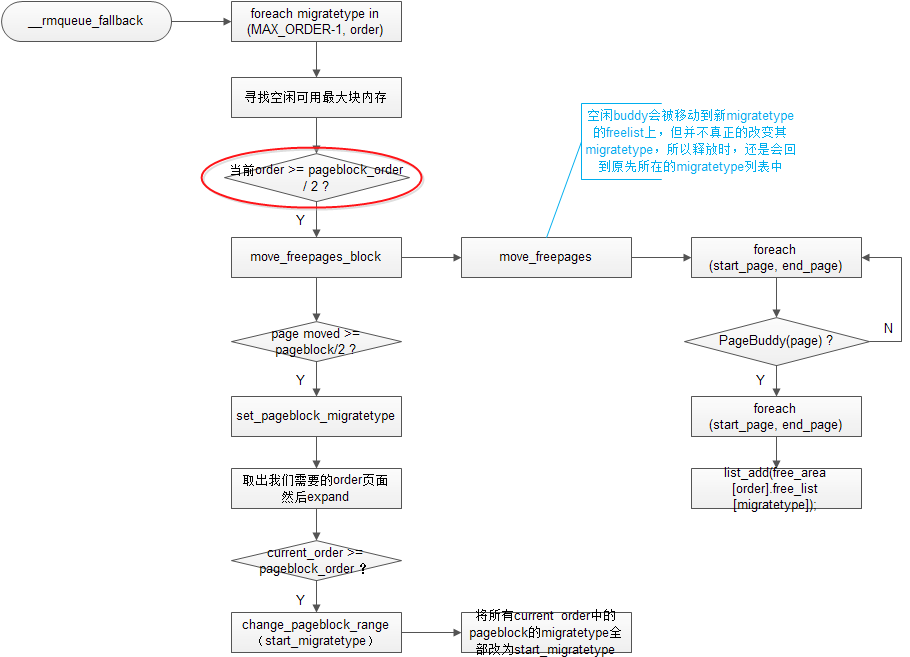
下面分析一下migrate type是如何改变的。还是有点小复杂的。
1)首先所有讲到fallback机制的资料上都会提醒我们注意,在从backup migratetype中取内存时,是从大的order往小order递减,直到我们需要的order,如果没有就返回NULL
2)第二点值得注意的是,并不是fallback机制一起作用,page的migratetype就会改变。而是在满足一定的条件的情况下才会发生。条件就是红圈中的,以及下面的page moved >= pageblock / 2。什么意思呢?就是说,当找到的这块大内存的order超过pageblock_order的一半,以7800为例,default pageblock_order是MAX_ORDER-1 = 10,则这块内存order要超过5,就是32个page。第二个条件就是,这块大内存所在的pageblock上有超过一半的空闲buddy。若满足这两点,这块内存所在的pageblock的migratetype会被修改,那么属于他且已分配出去的buddy在释放时,会被合并到新的migratetype中。
3)我们在测试上面所说的第二个条件时,会先将pageblock中空闲的buddy移到新的migratetype中,但并不真正的改变其migratetype。因为涉及到获取migratetype的操作,都是通过函数get_pageblock_migratetype来实现的。所以只要不修改整块pageblock的migratetype就不会影响到其下所有buddy的migratetype属性。
4)当找到的这块大内存超过pageblock时,会将其下所有的pageblock的migratetype都修改成我们所需要的migratetype。其实这里反映出的思想和上面是一样的,就是找到的空闲内存足够大,就迁移migratetype。
5)最后值得注意的一点就是,红圈中的条件判断其实不完整,真实代码中的判断是这样的:
if (unlikely(current_order >= (pageblock_order >> 1)) ||start_migratetype == MIGRATE_RECLAIMABLE ||page_group_by_mobility_disabled表示迁移特性关闭,也就是说页面并不受migratetype所限制,那页面应该可以随心所欲的迁移,实际上确实如此,后面如果page_group_by_mobility_disabled,也并不需要判断有多少free buddy,就可以迁移页面了。page_group_by_mobility_disabled) { …… }
另外一个,start_migratetype == MIGRATE_RECLAIMABLE就值得推敲了。所有代码中都没有看到对其的使用。网络上对其的解释是:
可回收页:不能直接移动,但可以删除,其内容可以从某些源重新生成
所以我认为MIGRATE_RECLAIMABLE因为很容易被释放(或叫回收),他也是MIGRATE_UNMOVABLE和MIGRATE_MOVABLE的第一替补,所以不管找到的空闲页面有多大,都应该尽可能的迁移给他。
——初始化/1536357494259)
——初始化/1536357494500)
——初始化/1536357494404)
——初始化/1537084962717)
——初始化/1537084962725)
——初始化/1537084962722)