1. UBOOT部分
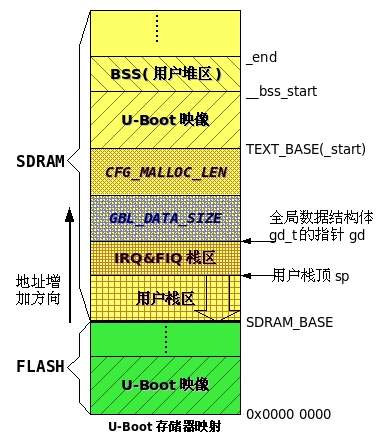
U-Boot使用了一个结构体gd_t来存储全局数据区的数据。UBOOT通过以下语句,将一个指向这个结构体放在r8寄存器中,此时,r8不会再做他用
DECLARE_GLOBAL_DATA_PTR
#define DECLARE_GLOBAL_DATA_PTR register volatile gd_t *gd asm ("r8")
在start_armboot中对该指针进行初始化
gd = (gd_t*)(_armboot_start - CONFIG_SYS_MALLOC_LEN - sizeof(gd_t));
在bootm command中对tag结构进行初始化。
run_command("bootm") -> do_bootm_linux -> setup_start_tag -> setup_start_tag(初始化params区域(数组),params = bd->bi_boot_params = (OMAP34xx_SDRC_CS0+0x100) = 0x8000_0100,d7800.c/board_init)
->……->setup_commandline_tag (将环境变量bootargs放入params数组,其tag为ATAG_CMDLINE)
params数组以tag为ATAG_NONE的tag作结束。params其实就是一组struct tag,定义为:
struct tag {
struct tag_header hdr;
union { // 各种tag
……
struct tag_cmdline cmdline;
……
}u;
}
2. kernel部分
在board-d7800.c中对mdesc进行初始化
MACHINE_START(D7800, "HSM D7800 Board")
/* Maintainer: Syed Mohammed Khasim - Texas Instruments */
.boot_params = 0x80000100, // 与UBOOT一致
.map_io = omap3_map_io,
.reserve = omap_reserve,
.init_irq = d7800_init_irq,
.init_machine = d7800_init,
.timer = &omap_timer,
MACHINE_END
在setup_arch(&command_line);中引用parse_tags(tags),以tag.hdr.size = 0为循环终止条件,遍历params区域(即struct tag数组),并通过该param的tag(ATAG_xxx)在.taglist.init区域中寻找合适的处理函数。对于ATAG_CMDLINE,其对应的处理函数即为parse_tag_cmdline,即将tag->u.cmdline.cmdline copy到default_command_line数组中,在setup_arch函数中,就是from数组。
tag->u.cmdline.cmdline => default_command_line => boot_command_line => comdline_p => command_line => static_command_line (setup_command_line中实现)
对于.taglist.init的配置,是通过引用一系列的如下的宏来实现的
__tagtable(ATAG_CORE, parse_tag_core);
__tagtable(ATAG_MEM, parse_tag_mem32);
__tagtable(ATAG_CMDLINE, parse_tag_cmdline);
这些宏其实就是将一组struct tagtable放到.taglist.init区域中,此区域可以用__taglist_begin, __taglist_end来表示
在start_kernel中,系统调用以下函数,真正 的处理params
parse_args("Booting kernel", static_command_line, __start___param,
__stop___param - __start___param,
&unknown_bootoption);
该函数从static_command_line中取param出来,并用parse_one处理。parse_one会先以param的name去__param section中查找是否已经有此变量的定义,
1)如果有此定义,则直接调用该param的kernel_param_ops(例如param_ops_bool = {.set = param_set_bool; .get = param_get_bool})
2)如果没有定义,则调用handle_unknown,即unknown_bootoption
unknown_bootoption -> obsolete_checksetup(param)
obsolete_checksetup函数会遍历__setup_start~__setup_end区域,假如在此区域中找到param对应的obs_kernel_param,则调用该obs_kernel_param的setup_func(其实init参数就是在此时被处理的)。
3)如果param在__setup_start~__setup_end中仍然没有对应的处理的话,则会放到envp_init中
* obsolete是过时的意思,从中可以看出linux中认为param参数是以后主要使用的启动参数传递方式,将慢慢摒弃__setup的形式,通过module_param的方式可以在启动参数中为驱动的参数赋值,这种赋初值的方式将成为主流
* 关于__setup_start~__setup_end区域的初始化,参考以下内容
init/main.c里有如下一行
__setup("init=", init_setup);
展开后
__setup_param(str, fn, fn, 0)
static const char __setup_str_##unique_id[] __initconst \
__aligned(1) = str; \
static struct obs_kernel_param __setup_##unique_id \
__used __section(.init.setup) \
__attribute__((aligned((sizeof(long))))) \
= { __setup_str_##unique_id, fn, early }
一些编译参数:
__initconst: __section(.init.rodata),将该变量放入名字为“.init.rodata”的段中
__used:告诉编译器无论 GCC 是否发现这个函数的调用实例,都要使用这个函数。这对于从汇编代码中调用 C 函数有帮助
__attribute__:gcc的标志,为函数和变量设置属性,以增强编译的功能,可用编译时参数WALL打开
在start_kernel->setup_arch中对启动参数的处理:
1.mdesc = setup_machine(machine_arch_type);所获得的machine_desc没有fixup成员。其定义在arch/arm/mach-omap/board-d7800.c中
2.依上,则char *from = default_command_line = CONFIG_CMDLINE = "root=/dev/mmcblk0p2 rootwait console=ttyO2,115200"
3.strlcpy(boot_command_line, from, COMMAND_LINE_SIZE);
4.strlcpy(cmd_line, boot_command_line, COMMAND_LINE_SIZE);
5.*cmdline_p = cmd_line; parse_early_param();
start_kernel调用
parse_args("Booting kernel", static_command_line, __start___param,
__stop___param - __start___param,
&unknown_bootoption);
来处理,定义在以下段中的param
__start___param = .; *(__param); __stop___param = .
gd指针只有在需要使用它的函数中定义为一个局部变量:
DECLARE_GLOBAL_DATA_PTR
因为在u-boot中,这个指针使用一个固定的寄存器来保存它,所以即使是局部变量,但是它在所有使用到它的地方都是一样的值,这个值在board_init_f中初始化,指向CFG_GBL_DATA_ADDR