0%
SpaceVim gtags and cscope
SpaceVim为gtags和cscope分别提供了独立的layer。本篇重点介绍一下这两个layer的使用思路和方法,以及现在的bug。先说结论,虽然我打算migrate到SpaceVim了,但是我打算放弃这俩layer,因为bug的问题,导致不可用。所以还是自行配置插件来使用吧。
gtags
在使用SpaceVim之前,没有听说过gtags+global这一套tag查询工具。也是看了SpaceVim gtags layer才想试试看。
命令行使用gtags+globa
如果是在命令行使用gtags,需要:
- 项目代码树根部,生成GTAGS文件,方法就是运行gtags命令
- 然后就可以在项目的任何位置,使用global命令来查询你需要的信息。
具体可以查看gtags和global的man page。
SpaceVim的gtags layer
先看一下gtags layer的快捷键:
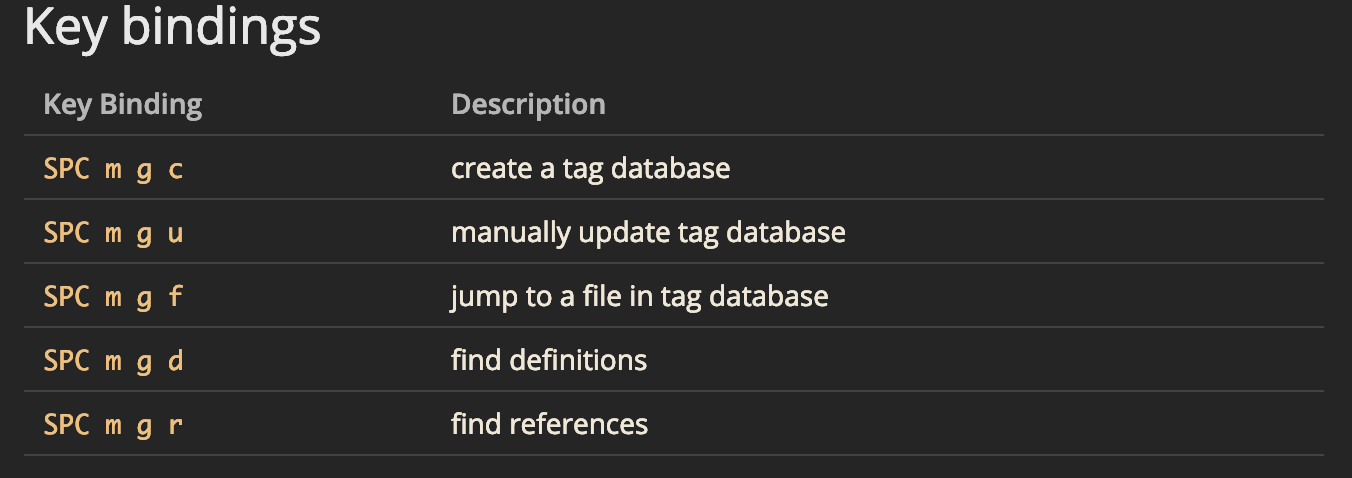
:GtagsGenerate[!] {bang}
Update gtags for current file, with a {bang}, will update the project's gtags database.:Gtags -r func
To go to the referenced point of func, add -r option.:Gtags -f main.c
To get list of objects in a file 'main.c', use -f command.:Gtags -f %
If you are editing `main.c' itself, you can use '%' instead.
那么实际使用效果如何呢?
[SPC]mgc在~/.cache/SpaceVim/tags/<project_root_path>下生成了GTAGS文件。这里的project_root_path是用下划线取代了斜线的字符串,例如:我的linux源码树在/Users/user/linux,那么对应的tag目录就是~/.cache/SpaceVim/tags/_Users_user_linux_。
[SPC]mgd也可以顺利跳转到函数定义,[SPC]mgr可以跳转到函数引用处,而且会用quickfix窗口显示搜索结果。
问题
快捷键定义出来的功能似乎都很好,没有什么问题。问题出在 :Gtags -f %。
这个功能可以方便搜索本文件的函数定义。配合Denite,就可以用在tagbar窗口中搜索了。
在命令行里执行该命令后,出现错误Error: No tags found in xxx。但明明文件里的函数定义跳转已经可以了,没有道理出这个错误。
产生这个错误的源文件是$HOME/.cache/vimfiles/repos/github.com/SpaceVim/gtags.vim/autoload/gtags.vim。
$HOME/.cache/vimfiles/repos/github.com/SpaceVim/gtags.vim/是gtags插件的repo,托管在GitHub上。
发生错误的函数是s:ExecLoad。流程大概这样:
- lcd到.cache目录下的tags目录
- 执行命令globa --result=ctags-x -qf <relative file path>
- 用命令e返回原目录
- 解析命令返回的结果,并显示
于是按照插件的流程执行命令,不出所料,结果返回是空的。
如何将GTAGS文件放在源码树意外的指定目录?
先看官方教程:
方法一
If your source files are on a read-only device, such as CDROM, then you cannot make tag files at the root of the source tree. In such case, you can make tag files in another place using GTAGSROOT environment variable.
$ mkdir /var/dbpath
$ cd /cdrom/src # the root of source tree
$ gtags /var/dbpath # make tag files in /var/dbpath
$ export GTAGSROOT=`pwd`
$ export GTAGSDBPATH=/var/dbpath
$ global func
通过设置两个环境变量GTAGSROOT和GTAGSDBPATH,来实现srouce和tags的绑定。这也是我的PR的解决方案。
方法二
There is another method for it. Since global(1) locates tag files also in /usr/obj + <current directory>, you can setup like follows: It is ’obj’ directory.
$ cd /cdrom/src # the root of source tree
$ mkdir -p /usr/obj/cdrom/src
$ gtags /usr/obj/cdrom/src # make tag files in /usr/obj/cdrom/src
$ global func
The -O, --objdir option does it automatically for you.
这里的意思是说,global会自动搜索/usr/obj+<current directory>下的tags文件,所以用gtags将tags文件生成到/usr/obj下,也可以达到效果。另外最后一句的意思是,如果用'-O'或'--objdir',不跟目录名,gtags会直接将tags文件生成到/usr/obj下。
这里的/usr/obj也可以通过环境变量MAKEOBJDIRPREFIX或GTAGSOBJDIRPREFIX来指定。官方推荐用前者,后者已经deprecated了。
再看插件作者的问题
gtags插件作者使用gtags#update函数来更新GTAGS文件,其对应的命令是
gtags -O <tags path in .cache>。显然是这里对官方文档的理解出问题了。gtags -O并不是用来绑定source和tags,且也不需要跟路径名。
可惜的是,虽然我提了PR,但似乎作者并没有意识到问题出在哪儿。
cscope
cscope之前一直是我的主力tag查询工具,虽然有人诟病cscope已经久不更新(最近一次更新是2012年),可能被弃坑了,但确实好用,也没见有什么bug。所以在试用SpaceVim的时候,重点考察了一下cscope layer。
不过,令人遗憾的是,这个cscope layer看起来根本是一个笑话。完全是不可用状态。
:[SPC]mci
创建cscope数据库,结果返回错误Vim(call):E117: Unknown function: cscope#createDB。
查了一下源码,根本就没这个文件。
cscope layer的实现在HOME/.cache/vimfiles/repos/github.com/SpaceVim/cscope.vim/,同样托管在[GitHub](https://github.com/SpaceVim/cscope.vim)。layer的快捷方式绑定在HOME/.SpaceVim/autoload/SpaceVim/layers/cscope.vim。
cscope想做到的
通过理解cscope.vim源码,可以大概了解这个layer想做的思路。基本上和gtags思路类似,就是在源码树意外的目录下生成cscope.out文件并通过cscope add命令来添加。
function! cscope#preloadDB()
let dirs = split(g:cscope_preload_path, s:FILE.pathSeparator)
for m_dir in dirs
let m_dir = s:CheckAbsolutePath(m_dir, m_dir)
if !has_key(s:dbs, m_dir)
call s:InitDB(m_dir)
endif
call s:LoadDB(m_dir)
endfor
endfunction
可见这里是从全局配置g:cscope_preload_path中解析出一系列目录。这里的s:FILE.pathSeparator = ':'
这个s:InitDB会使用s:CreateDB来创建cscope db文件。CreateDB使用这条命令来创建cscope db:cscope -b -i <cscope_vim_dir><time stamp>_inc.files -f <cscope_vim_dir><time stamp>_inc.db
-i参数指定文件名而不用默认的cscope.files,-f参数指定文件名而不用默认的cscope.out。
再往下看s:ListFiles还可以指定了过滤的目录,使用全局配置g:cscope_ignored_dir。感觉一切想法都不错,只可惜致命bug导致不可用。且没有丝毫文档解释这些配置的用法是什么,虽然能猜到作者的用意,但毕竟不明确,PR都不知道怎么提。所以就暂且搁下了。
总结
gtags和cscope layer的想法都不错,将文件生成在单独的cache目录,防止污染源码树,毕竟这些tag文件一堆,git命令的显示就会混乱,容易造成误操作。但是都有很严重的bug。不知道作者的发布思路是什么。gtags还好一点,主要功能还能用,cscope直接连创建的命令都不能使,未免有点太夸张了。希望作者尽快修复。或者提供多一点的文档,方便大家社区协作。
SpaceVim试用体验
初见
第一次认识SpaceVim是在阮一峰的每周分享博客上。本人一直是一个Vim控,长期致力于折腾Vim各种工具,也不知道真的能提升多少效率,但就是爱折腾。之前一直使用spf13的vimrc配置,也有好几年时间了。这次一见SpaceVim,瞬间有一种莫名的高级感。但初试之下,又发现工作方式与spf13的配置或者插件集相差很大。无法立即迁移,于是便心生试用一段时间的想法。
本人Vim的常用场景是:
- 看代码,编辑代码,主要是C/C++,顶多加上python,javascript
- 要求支持cscope,tags
- 方便强大的grep + quickfix
- 自动补全 + snippets
下面针对这几个场景一一谈谈SpaceVim的使用体验
SpaceVim介绍
按下本人的需求不表,先聊一聊SpaceVim本身标榜的和我觉得比较有特色的feature。安装啥的就不说了,直接官网都有介绍,curl+bash分分钟搞定的事情。
welcome page
SpaceVim让我一件倾心的就是这个welcom page。花哨的主题,别致的status line,还能选最近打开的文件。颜值与功能都在线。
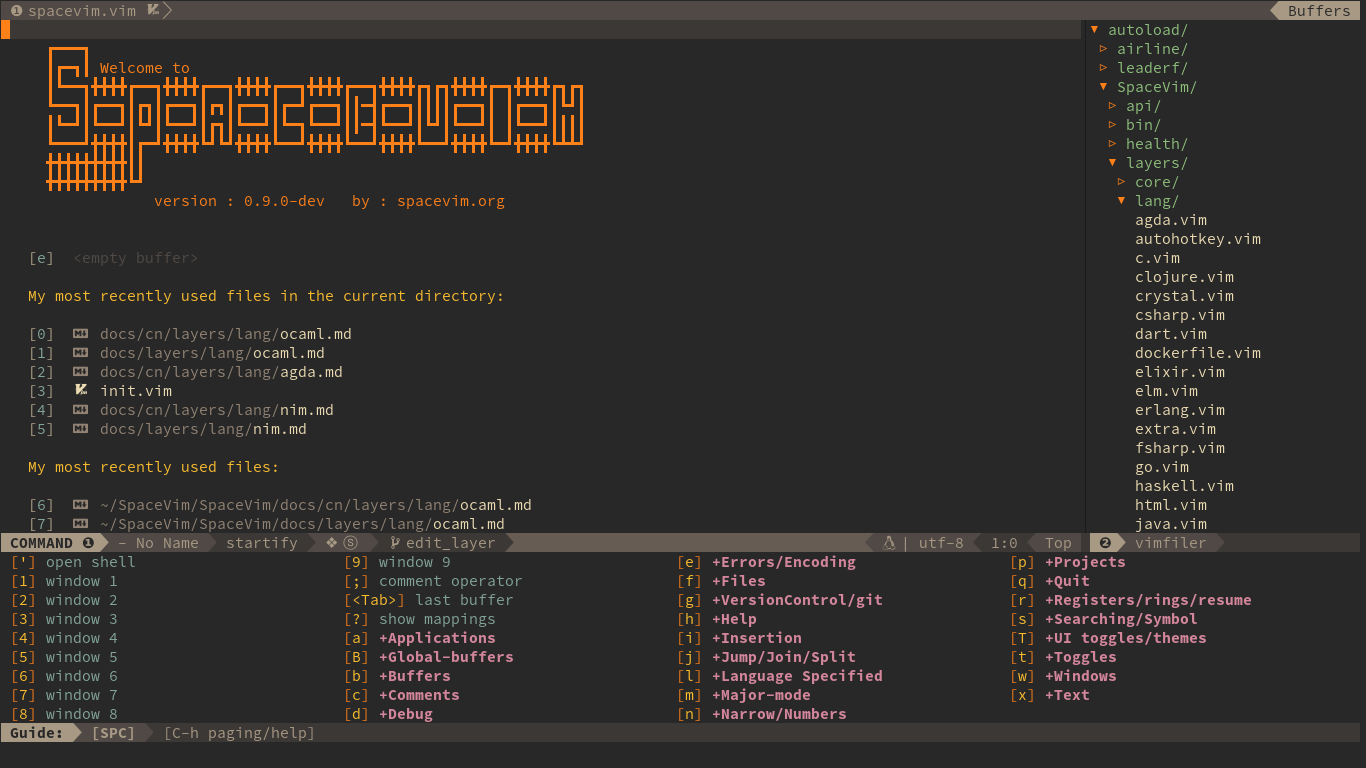
是不是很炫酷,这张图的主界面就是welcome page。可以在上面选择最近打开的项目。当你切换路径时,这些项目也会跟着更新。
下面是vim-which-key(纠正:不是vim-which-key,经作者说明,是SpaceVim 内部集成的leaderguide, 基于一个很老的插件上修改的),可以提示快捷键。解决了vim初学者的痛点。
右侧是SpaceVim的默认文件管理器vimfiler界面。同时,你也可以选择老牌的NERDTree或者最新的defx。他们各擅胜场,没有绝对的优劣。
flygrep
flygrep目前已经从SpaceVim中独立出来,也就是说普通的Vim用户也可以独立安装使用该插件。
所谓的flygrep也就是一个异步搜索的工具。不用等待搜索完全结束才能查看搜索结果。而是结果列表不断的被填充。另一个优点是对搜索结果的过滤集成了类似denite的fuzzy finder。但是不能做到denite的强大配置。
放个动图,感受一下grep on the fly的异步搜索:
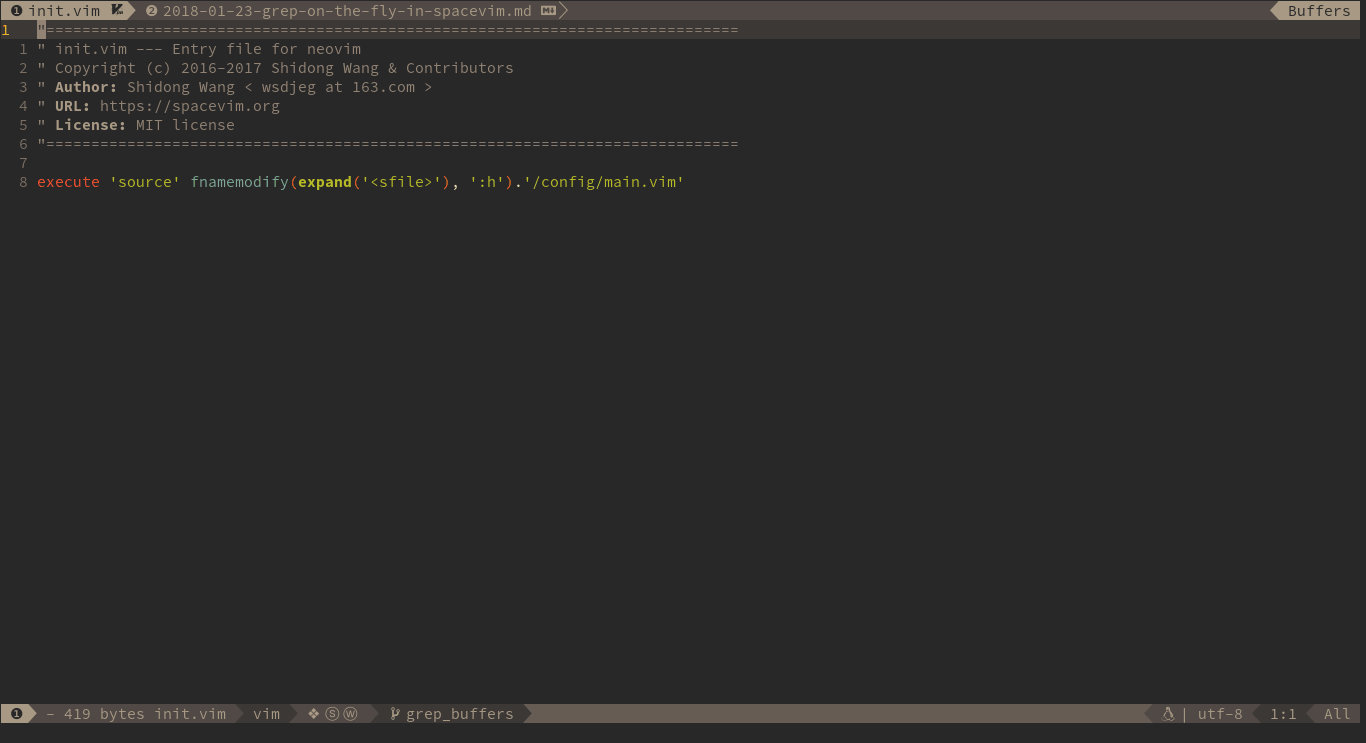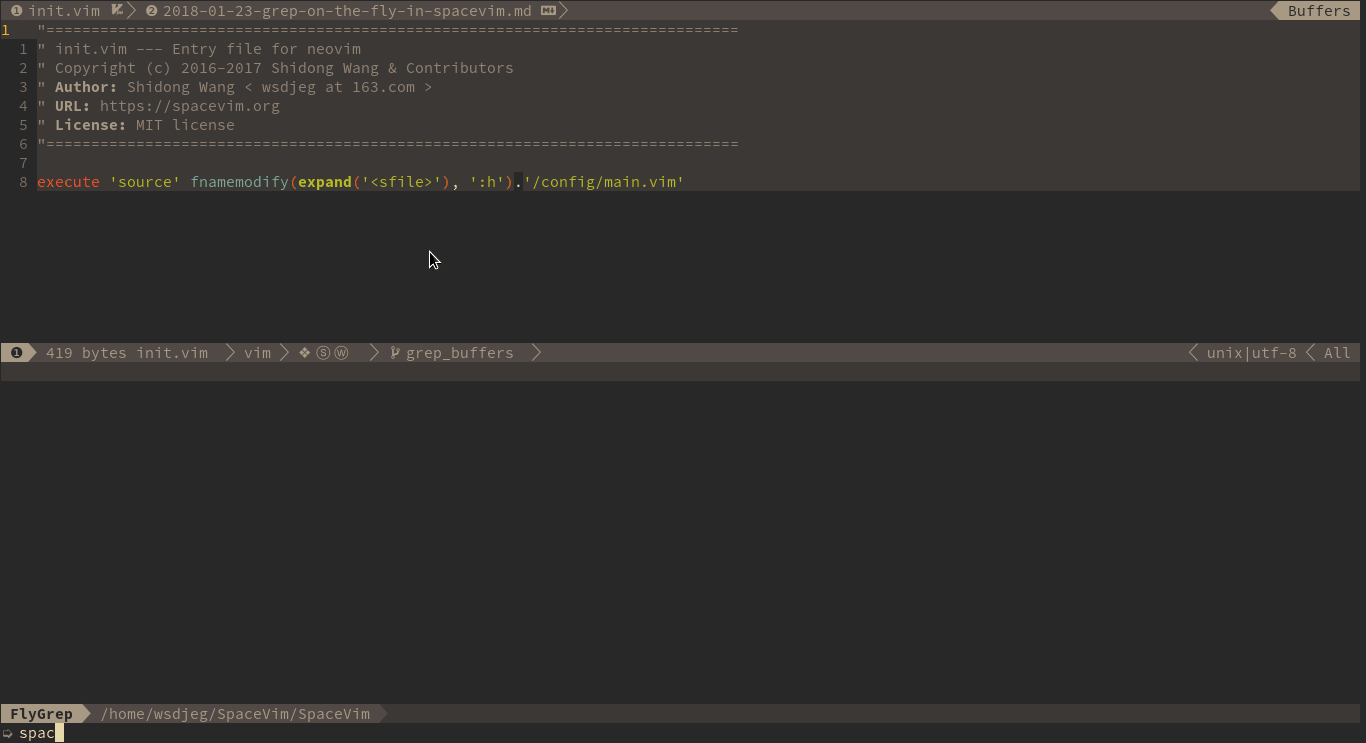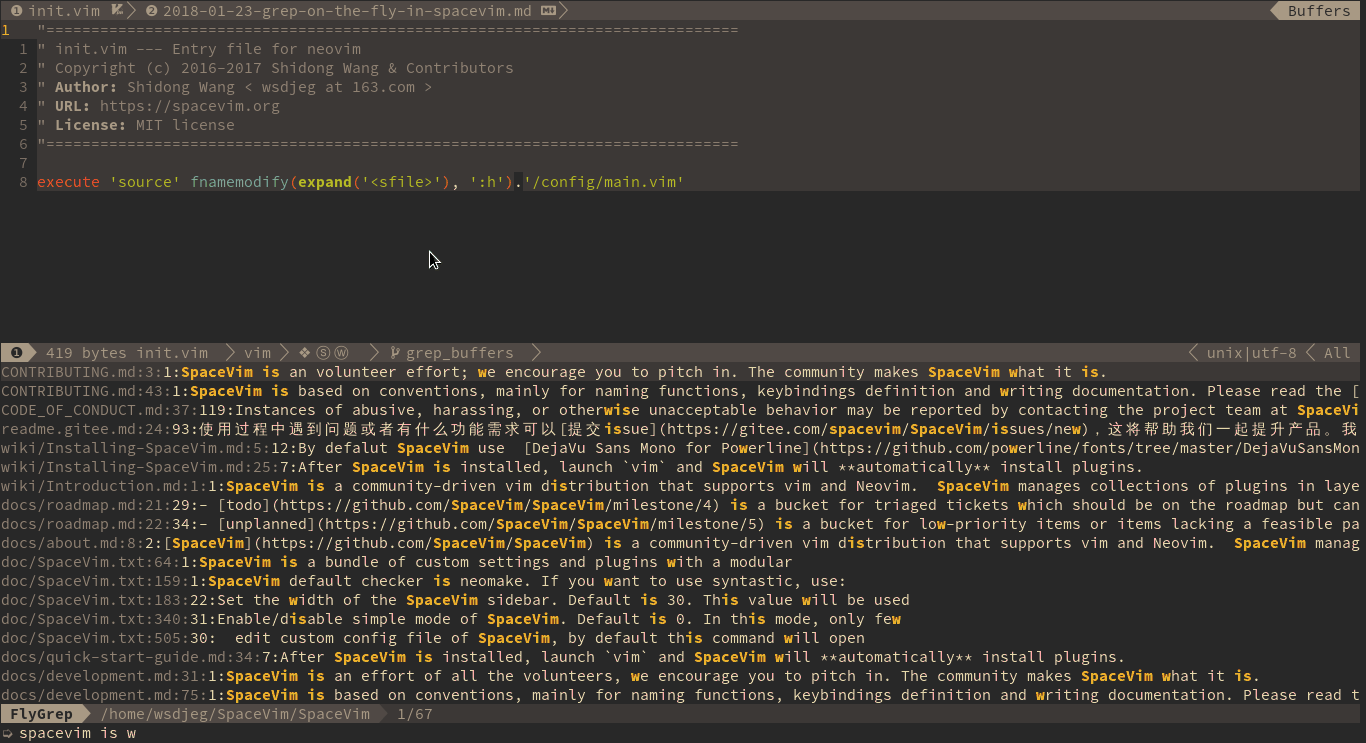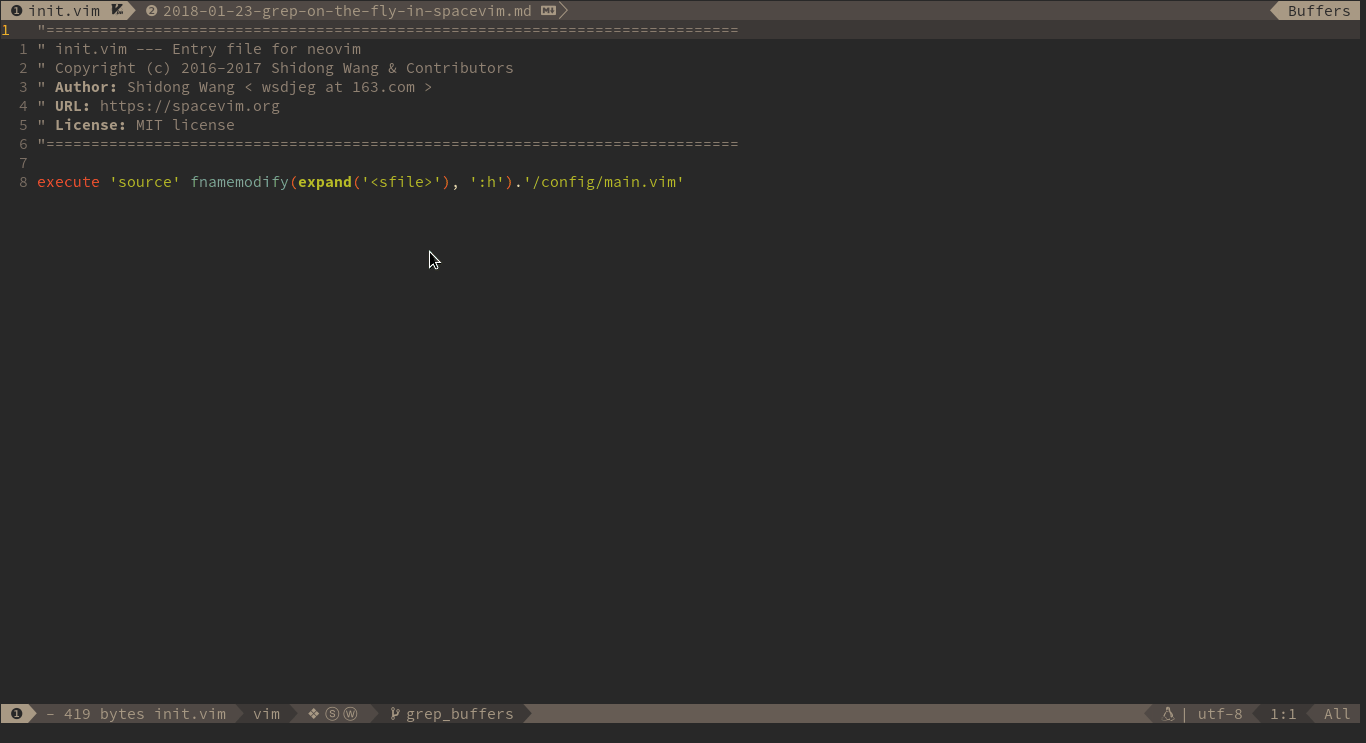
使用下来,感觉虽然可用,好用,但功能不够强大。不能随心所欲的制定搜索策略。比如设置文件过滤啊,搜不搜hidden文件啊,等等。其实也就是不能对类grep工具,例如rg,ag,ack,grep等等,物尽其用。
Asynchronous plugin manager
先放官网动图感受一下:
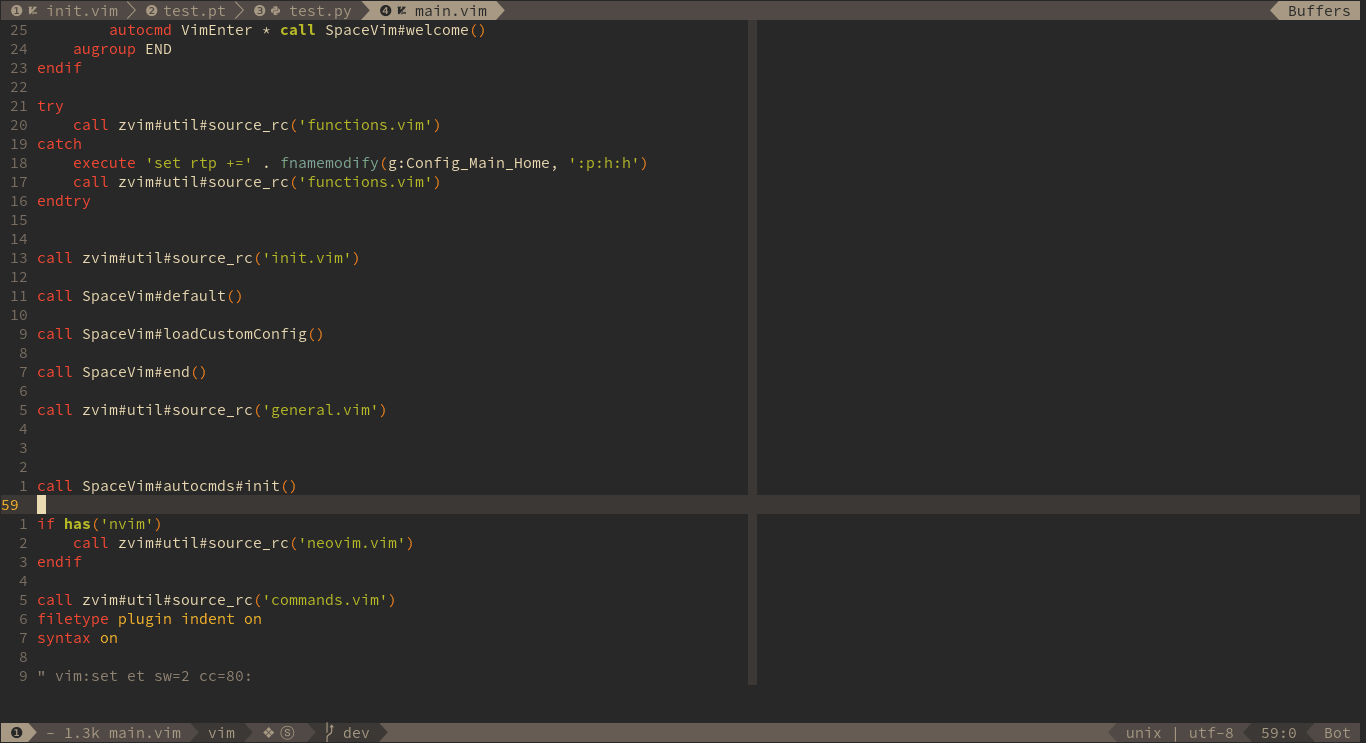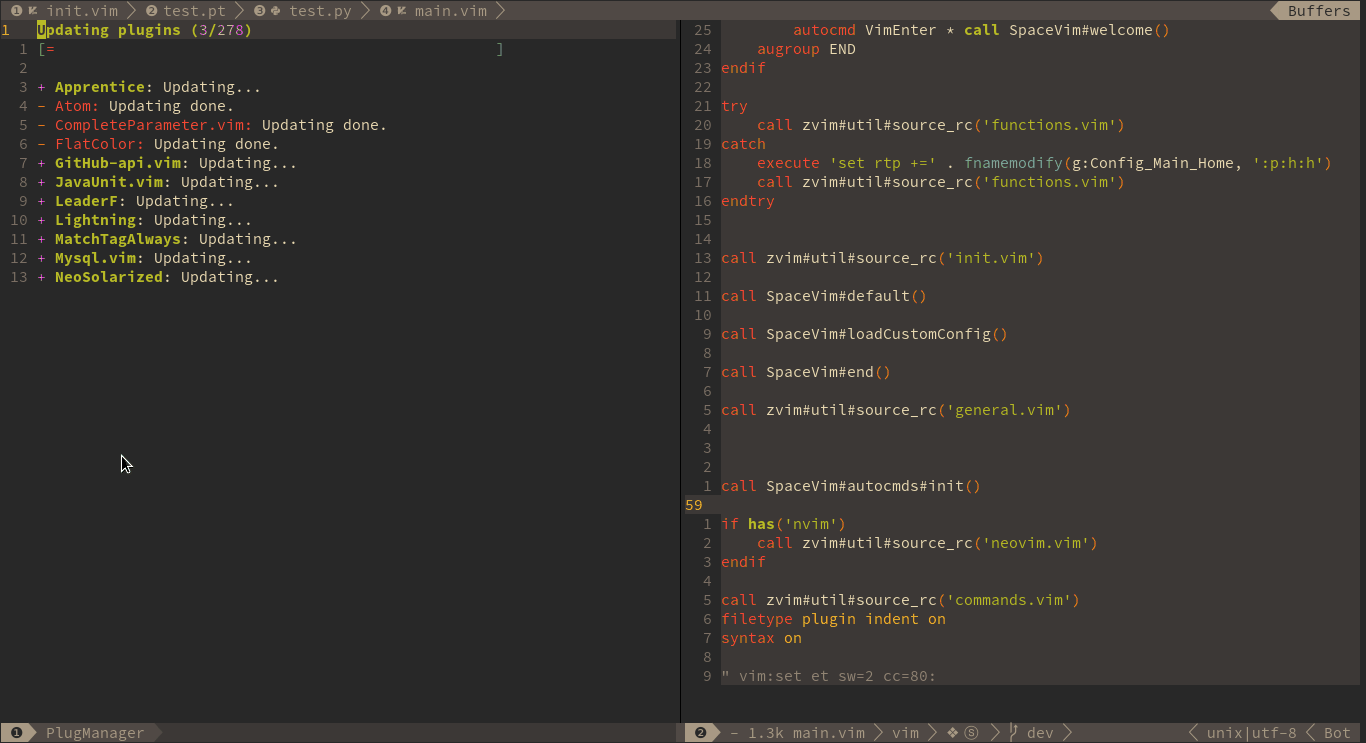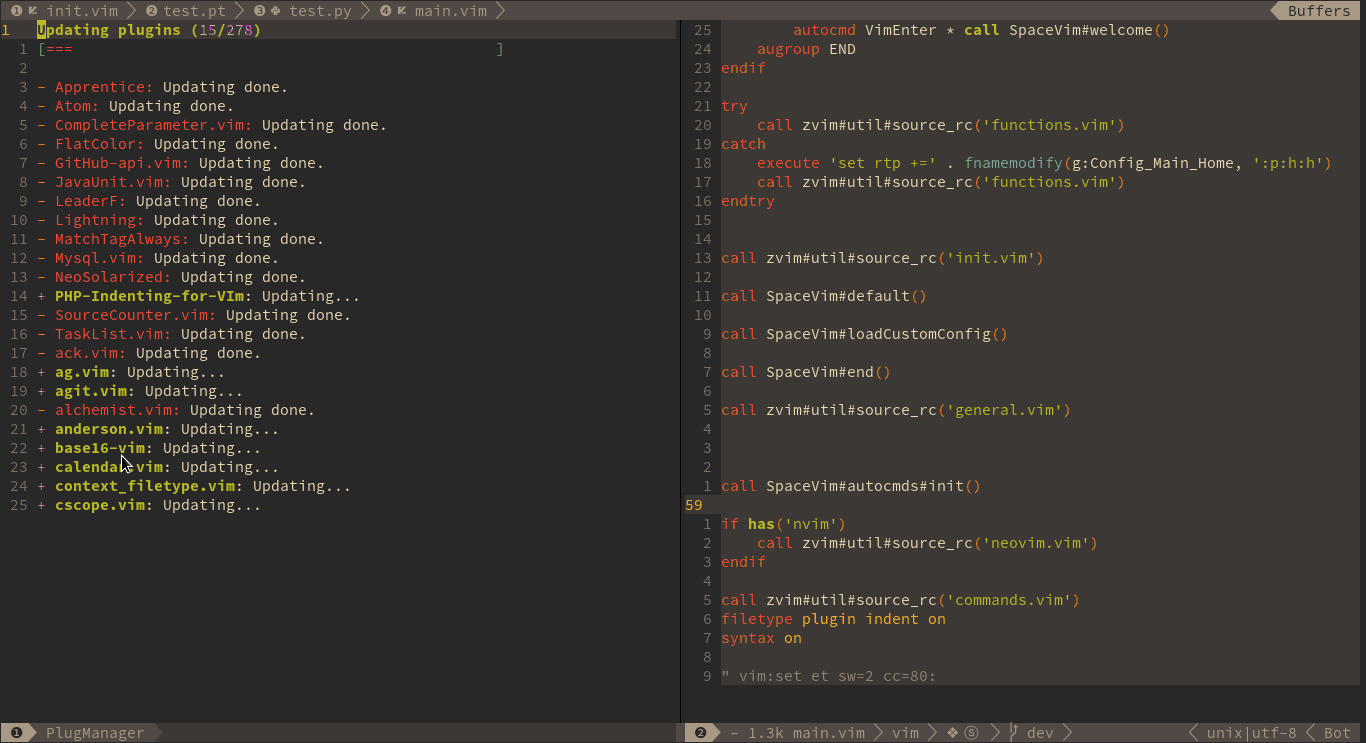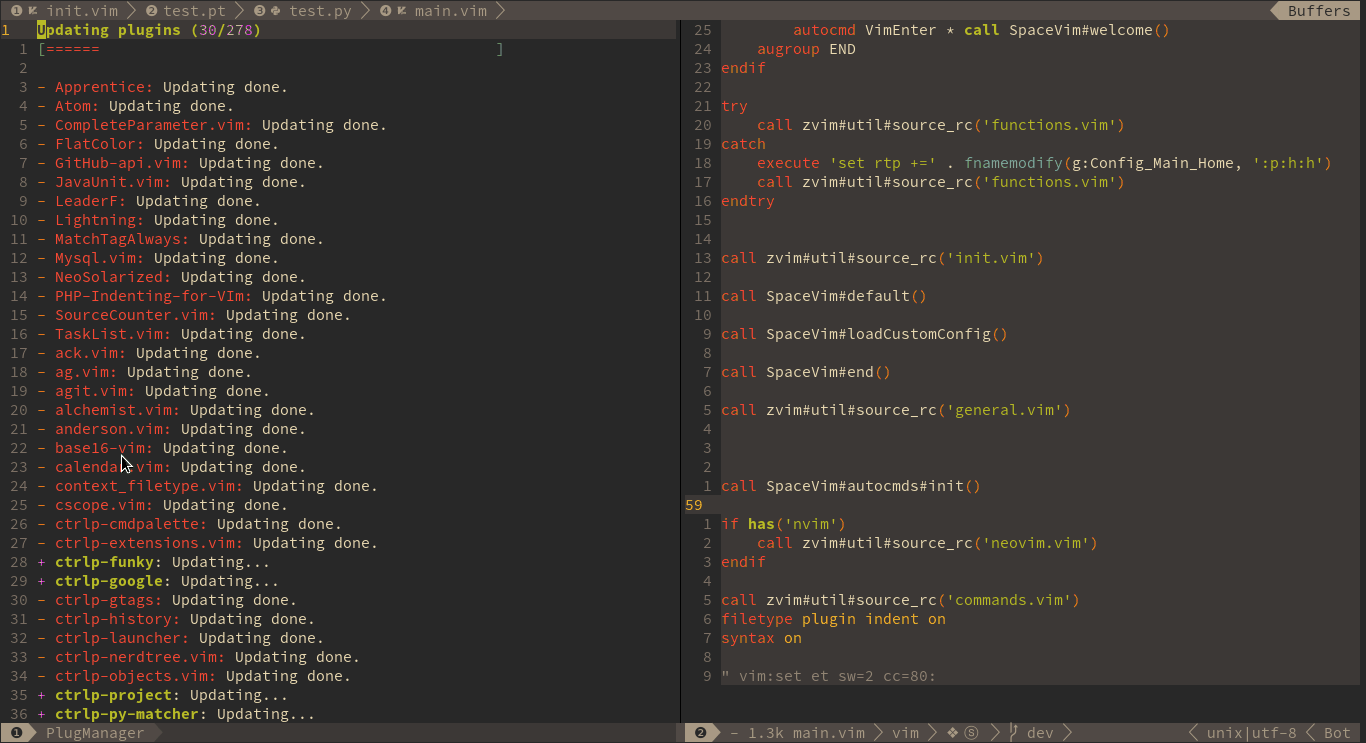
SpaceVim采用了Shougo大神的dein插件管理器。和老牌的Vundle比呢,就是可以异步操作,速度上和使用体验上提升了一个等级。Vundle安装插件是要一个一个来的,上图里面dein就可以大家一起来,并发操作。
layers
SpaceVim一大特色就是基于layers来管理插件集合和配置集合。据说是学spacemacs的。目前SpaceVim提供的layers在Available layers可以看到。在init.toml中可以配置。功能挺强大。
不过spf13中就有这样的概念,不过spf13通过的是vim的g:变量来管理,听起来没有SpaceVim这么酷炫。
另外,虽然现在layer已经挺丰富了,但试用下来,感觉对我这样的Vim老菜鸟,并没有什么质的提升。目前尝试过下面几个layer:
-
autocomplete:这个必须要使用的,基于neocomplete或者YCM。没感觉到和裸vim上使用有什么差别
-
cscope:这个提供基本cscope的快捷键,且可以帮助管理cscope数据库文件
-
denite:这个就比较强大了,Shougo大神的插件,使用很复杂,但是功能也真强大,放到后面说
-
leaderf:这个也很厉害,据说是国人写的,搜索速度比纯grep不知道强到哪里去了,但是SpaceVim目前对其支持还没到位。另外相比denite+现代grep(例如rg,ag),速度也没有很大的优势,但是界面要易于上手一些。
-
gtags:类似cscope,就是工具变成GNU global
-
lang#c/python/sh/vim:提供各语言的相关插件,没感觉出来有什么特别的。可能更多的是自动补全的整合和格式的调整吧。
-
language-server-protocol:这个对于我是一个很新的概念,使用过IDEA类IDE的同学一定对IDE的强大印象深刻。我本来以为lsp能让Vim达到IDEA那个水平,提供类似:
- 基于编译级别的补全提示
- 语法检查
- 文档查询
但似乎是我太理想化了,显然现在的language server还做不到。因为工作在C环境,尝试过clangd和cquery。都不太可用。但感觉这是未来发展的方向。有一天Vim也能发展到VS code那样。
-
shell:提供内嵌命令行,可用,但是貌似bug很多,还不如Ctrl+Z切出去省心。
-
sudo:这个很好,解决了一个痛点。就是开启文件后,如果忘记打sudo开启,可以在保存的时候申请sudo权限。
-
tmux:提供了Vim和tmux的深度整合。例如并排开了两个tmux window,每个window开了一个SpaceVim,那么这两个窗口之间,就可以通过指定的快捷键进行跳转。但有个小问题,该layer会更改tmux的主题,但是似乎更改后的主题对tmux的功能支持不好。例如,prefix+m标记window的时候,标签上不显示那个小m。还不是很完美。
SpaceVim体验
回到我的需求上来,挨个验证SpaceVim能不能满足要求。
代码跳转
cscope/tags
原生Vim对tags, cscope的支持不变。也就是说
- 在有tags文件的情况下,ctrl+]跳转仍然可用,没有问题
- 在链接了cscope.out的情况下,所有cs find操作也仍然可用,且如原生Vim一样,可以通过quick fix窗口操作。
也就是说,SpaceVim至少守住了下限,Vim提供的功能没有被破坏。兼容性不错,点个赞。
gtags
在tags,cscope之外,还有个gtags,这个是通过GNU提供的二进制工具gtags来建立索引,通过global工具来搜索, 这俩是一套。官网链接在此:global。
globa提供了类似cscope的功能,也可以搜索饮用,也可以grep。功能同cscope有点重复。Vim通过一个古老的插件gtags.vim对其提供支持。
SpaceVim通过一个gtags layer对gtags也提供了支持。当你在init.toml中enable该layer时,SpaceVim就会激活一个叫Gtags的命令,它由SpaceVim的gtags layer提供。
基本功能可用:
- :Gtags -x func可以查找定义
- :Gtags -r func可以查找饮用
- 其他命令可以通过:h Gtags查看帮助。帮助文档清晰易用,给作者点个赞。
在我看来,Gtags的唯一好处是可以和Denite融合。这个放到Denite那里再说,总之就是方便过滤搜索结果。
说完Gtags的好处,现在开始吐槽。我很想要的一个功能却有bug。根据文档:Gtags -f %可以显示本文件的文件名,但一执行就报错:“Error: No tags found in xxx”。debug出来原因是因为调用global工具前,环境变量没设置正确。目前已经给作者提供了PR,但似乎作者并没有意识到这个问题,一直没有被pick。关于这个bug可能另开一篇比较合适。如果和我遇到同样问题,可以试试我的fork——zhougy0717/gtags.vim
随心所欲的搜索
FlyGrep是SpaceVim的一大卖点。FlyGrep可以支持多种搜索工具,按照使用优先级是: rg, ag, pt, ack then grep。从SpaceVim的搜索快捷键配置上可以看出,作者可能确实颇用心在猜测用户的使用场景。感受一下吧:
[SPC] + s

[SPC] + s + a

自动补全
通过SpaceVim autocomplete实现。其底层依赖的插件是Shougo/deoplete.nvim。不知道和原生Vim+插件有什么差别。SpaceVim提供了一些特别的快捷键,但不知道有啥用。总体体验,至少不低于原生Vim。
SpaceVim提供的增强功能
Denite集成
是SpaceVim让我认识了Denite,但Denite并不依赖于SpaceVim。也就是原生Vim也可以使用Denite插件。Denite是Shougo大神新出的插件精品,关于这个的介绍也有很多了。Denite的作用是使用fuzzy finder来过滤Vim中的各种信息。这些信息就是Denite source。Denite本身支持一些source,另外也有一些external sourc可以安装。每个external source都是以一个Vim插件的形式存在。例如:ozelentok/denite-gtags是一个Denite过滤gtags搜索结果的插件。
Denite支持的source,可以通过:Denite source来查看,例如:
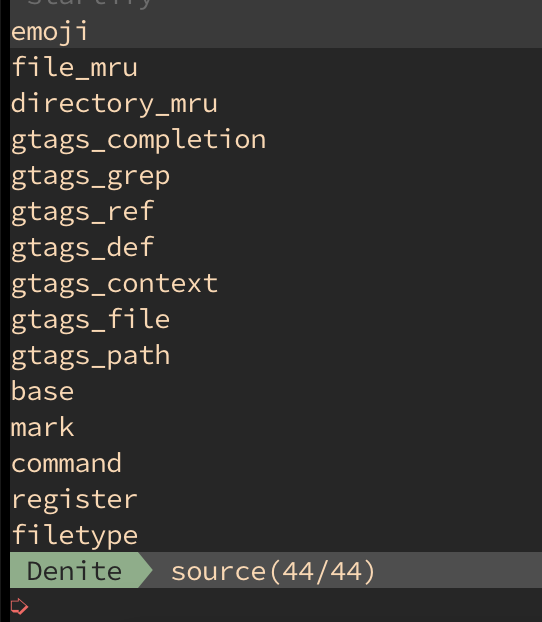
command, default_opts, recursive_opts, args[1]..., pattern_opt, args[2]..., separator, args[0]... or final_opts] command line.
command, default_opts, recursive_opts, pattern_opt, separator和final opts是可配置参数。如果你用的是rg,可以在bootstrap脚本里这样配置Denite
call denite#custom#var('grep', 'command', ['rg'])
call denite#custom#var('grep', 'default_opts',
\ ['--hidden', '--vimgrep', '--smart-case'])
call denite#custom#var('grep', 'recursive_opts', [])
call denite#custom#var('grep', 'pattern_opt', ['--regexp'])
call denite#custom#var('grep', 'separator', ['--'])
call denite#custom#var('grep', 'final_opts', [])
- command: 设置默认运行的类grep命令,当然后面的选项和参数要和这个命令匹配
- default_opts: 可以设置你想要的参数
- pattern_opt: 设置grep命令对应的搜索正则的参数,例如:rg是--regexp,grep就是-E
- separator: 这个通常不用修改
- final_opts: 在路径后面,如果还需要输入参数,可以放在这里
关于arg[0..2],参考:
Source args: 0. path string or list of paths 1. string or list of arguments 2. pattern string or list of patterns
- arg[0]: 放需要搜索的路径名
- arg[1]: 可以放任意想放的参数
- arg[2]: 同上可以放任意想放的参数,因为跟在pattern_opt后面,可以放正则式。经过试验得知,这里的正则不是Vim正则,而是python正则。
有时候一些工具对参数顺序有关系,所以写的时候慎重。
例子:笔者用的是ag
搜索所有.c/.h/.cpp文件中的字符:Denite grep:./:'--cc':'\b__sched\b'
搜索.diff文件中的字符:Denite grep:./:'-G ".diff"':'\b__sched\b'
搜索包含隐藏文件:Denite grep:./:'--hidden':'\b__sched\b'
Welcome界面
如开篇所提,颜值功能都在线的Welcome界面,怎么都充满了高级感
方便的UI toggle
<Leader>+数字:选择对应的tab
Denite选择color schems
project管理功能:project目录,.project_alt.json
还有很多其他功能值得去发现
总结
SpaceVim目前bug还很多,例如NERD commenter的visual模式下基本不可用。Gtags,cscope都有问题。但毕竟瑕不掩瑜,基础功能不弱于原生Vim,还有其他这么多高颜值,好用的功能,相信SpaceVim未来也有一个好的发展。
tmux + vim的复制配置
做嵌入式的同学,大多在Linux环境下开发。现在也有很多同学用OSX开发。其实他们都是类Unix系统。作为一个开发者,效率很重要。有很多重复琐碎的动作,如果能提高一点效率,多次累积起来,节省的时间和精力也是可观的。在提升效率的同时,做一个很有效率,而避免琐碎重复的动作,也很有助于心情的愉悦。所以,但凡有机会,我都会给别人安利一些好用的工具,例如tmux,vim,fish啊,等等。
有人称tmux, zsh, vim是文本处理的三剑客。这三个工具用好了确实好用。我目前的开发环境使用的是fish + tmux + vim。fish的作用和zsh差不多。本文想着重介绍的是困扰我很多年的tmux + vim的剪贴板问题。
tmux下的复制
在毕业后的若干年内,我一直在Windows下,使用putty + ssh +tmux连接远端的Linux服务器做开发。好处是,tmux可以做session管理,即便putty ssh关闭,任务不会中断。只要服务器不关闭,下次打开仍然可以快速恢复工作现场。
tmux分屏模式下的文本选中
tmux中的panel在多任务的情况下非常好用。但带来的问题是,当tmux有横向分屏的时候,复制好困难。文本的选中会跨越panel边界(图截不出来,相信使用tmux的新手同学,应该都遇到过这个问题)。解决的办法是,打开tmux的鼠标模式:
set-option -g mouse on
此时,如果通过鼠标选中,就不会跨越分屏边界。怎么复制,对于新手来说,又是一个问题。
vim用:vsplit命令分屏的时候,也有同样的问题,解决方法如出一辙,使能鼠标模式,set mouse=a。
tmux复制模式下的复制
tmux的所有操作都是通过bind-key实现的。本身有一套默认的bind-key table,当然也可以自定义,tmux插件也可以帮你定义。所以有什么不清楚的,可以直接自行查bind-key table。方法是:
- 通过
ctrl + [:进入tmux命令模式 - 执行
list-keys命令就可以了
这里需要注意的是较新的tmux 中的bind-key table较老版本的完全不同。例如笔者当前使用的最新release版tmux2.8,而Ubuntu 16.04 LTS版本源中自带的是tmux 2.1。据说tmux中间进行过重构,导致很多功能其实并不兼容老版本。所以推荐使用新版本。
Ubuntu 16.04 LTS版本的源中自带的tmux是2.1的。这会导致很多功能没法使用
# tmux 2.8 list-keys bind-key -T copy-mode C-Space send-keys -X begin-selection bind-key -T copy-mode C-a send-keys -X start-of-line bind-key -T copy-mode C-b send-keys -X cursor-left bind-key -T copy-mode C-c send-keys -X cancel bind-key -T copy-mode C-e send-keys -X end-of-line bind-key -T copy-mode C-f send-keys -X cursor-right bind-key -T copy-mode C-g send-keys -X clear-selection bind-key -T copy-mode C-k send-keys -X copy-end-of-line bind-key -T copy-mode C-n send-keys -X cursor-down bind-key -T copy-mode C-p send-keys -X cursor-up # tmux 2.1 list-keys bind-key C-b send-prefix bind-key C-o rotate-window bind-key C-z suspend-client bind-key Space next-layout bind-key ! break-pane bind-key " split-window bind-key # list-buffers bind-key $ command-prompt -I #S "rename-session '%%'" bind-key % split-window -h bind-key & confirm-before -p "kill-window #W? (y/n)" kill-window是不是很不一样?请自行忽略2.1版本。
2.8中的每一行其实运行的是一个bind-key命令,具体参数可以参考tmux man page
- -T: 指定表格
- -r: 指定该按键可以repeat。例如调整panel大小,你不想每放大缩小一次都要按prefix吧,那会抓狂的。
copy-mode就是一个具体table,在你按下
ctrl + [进入复制模式时生效。同理还有个叫prefix的table,也就是普通模式下的按键表。
话说这么多,到底怎么复制?搜索这个表格的是否有copy-selection就可以了。所以通常Enter会被映射成send-keys -X copy-selection-and-cancel。也就是按下Enter,选中的文字会被复制到tmux剪贴板。
tmux下复制到Windows剪贴板
这个才是本篇想说的话题。因为我花了好些年才找到答案。所以可见经验的传承是多么重要。下面先说怎么做,再说为什么。
如何做?
首先单纯靠putty是没办法的,因为putty只是单纯的terminal emulator。而Linux的剪贴板管理是需要X-Window支持的。所以你需要的是一个完整的X11 forwarding的环境。X11 forwarding有很多途径可以做到,可以自行google,笔者选择了一个turn key solution,就是安装MobaXTerm。默认的配置就已经使能X11 server和X11 forwarding了。
接下来,要做的就是:
- 确定你的Linux系统里有X11界面,如果没有请自行google安装
- 确定你的Linux系统里有xclip, xsel或xclipboard三者之一
- 如果你的DISPLAY变量在tmux下不正常,可以在.tmux.conf下添加
set -g update-environment "\
DISPLAY \
"
- bind-key -T copy-mode y send-keys -X copy-pipe-and-cancel "xsel -i --clipboard"
最后一步更优雅的解决方法是安装tmux-yank插件。
为什么要这么做?
Linux的桌面系统管理了一个剪贴板,这个剪贴板依赖于X Window系统,由前述的几种app管理,类似于Windows下的clip.exe。当在Windows下用ssh连接Linux的时候,如果未设置X11 forwarding,则在Windows下是无法使用到xsel,xclip或者xclipboard的,所以无法访问Linux的剪贴板内容。如果设置好了X11 forwarding,则在Windows下就能访问Linux剪贴板。
tmux本身也管理了一个剪贴板,称为buffer。tmux的命令copy-selection, paste-buffer, list-buffers就是针对tmux自身的剪贴板的操作。tmux原生支持,通过空格选中,Enter复制,ctrl + ] 粘贴。
如果想tmux下将终端显示内容复制到Windows剪贴板要做的就是把tmux剪贴板发送到X11的剪贴板中。tmux-yank插件做的就是这件事。当然你也可以通过在copy-mode-vi表格里绑定任何按键来做这件事情。
vim复制到Windows剪贴板
没有运行在tmux下的vim或是gvim要复制到Windows剪贴板,或者说是系统剪贴板,依赖的是vim的寄存器操作。可以自行google。系统剪贴板对应的vim寄存器是"+。所以在vim下如果想复制到系统剪贴板,你可以用"+y来取代平时常用的y。例如:
- "+yy:复制当前行到系统剪贴板
- "+yw:复制当前的单词到系统剪贴板
如果vim运行在tmux下,因为tmux自带的剪贴板就有点麻烦了。这时候有一个插件就比较有用了——vim-tmux-clipboard。他依赖于另一个vim插件vim-tmux-focus-events。装好这两个插件,在.tmux.conf中添加
set -g focus-events on
大功告成。现在在vim下,直接使用yank快捷键,不用指定寄存器,就可以直接复制内容到tmux剪贴板,同时因为tmux-yank的存在,文本也会被复制到系统剪贴板。
Resource_Access_Protocol - PIP, PCP, SRP
常见的protocol有Non Preemption Protocol (NPP),Highest Locker’s Priority Protocol (HLP),Priority Inheritance Protocol (PIP,优先级继承),Priority Ceiling Protocol (PCP,优先级天花板),Stack-based Resource Policy (SRP)。后3者应用比较多,且他们呈现递进关系,PCP是PIP的改进,SRP是PCP的改进。本文主要针对PIP,PCP和SRP。
问题
Unbounded Priority Inversion
简单的优先级反转。
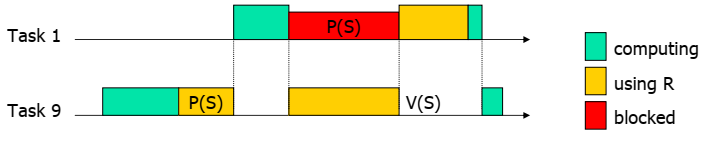
引入任务抢占后,优先级反转会导致不可预测的等待时间。这称为Unbounded Priority Inversion。
Dead lock
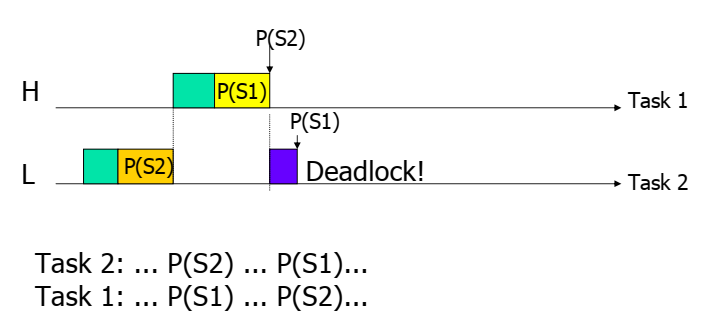
当有多个任务要请求多个资源的时候,则很有可能出现死锁的情况。
Transitive blocking
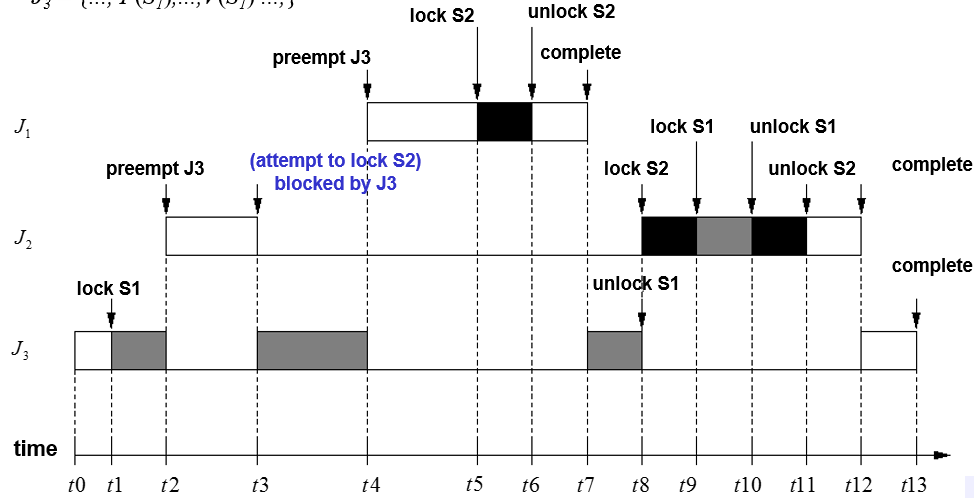
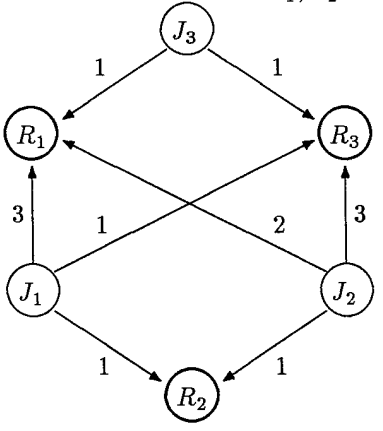
阻塞的传递,看下图
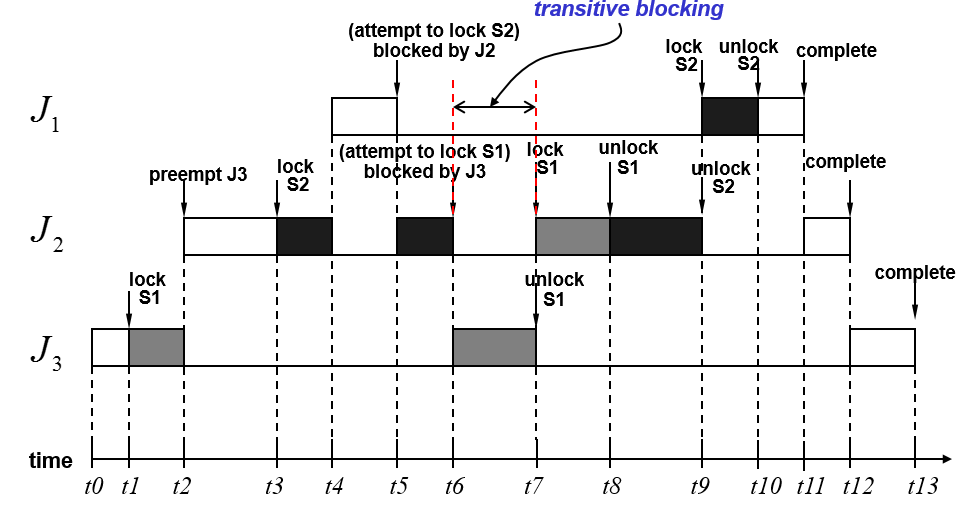
当有嵌套临界区的时候,就很容易产生阻塞传递。J1被J2阻塞因为S2,J2被J3阻塞因为S1,导致J1必须等待J3释放S1,然后J2释放S2之后,才可以顺利获得S2进入临界区。
Schedulability
PIP
定义
- direct blocking:普通的资源竞争。当一个任务申请的资源被另一个任务锁住时,即是direct blocking。
- push-through blocking: 因为priority inversion导致的阻塞。
算法
- A gets semaphore S
- B with higher priority tries to lock S, and blocked by S
- B transfers its priority to A (so A is resumed and run with B’s priority)
- A finishes its critical section and back to original priority before it enters the critical section
优点
因为当前占住资源的任务,始终以最高优先级在运行,中等优先级的任务就不可能抢占低优先级任务,所以解决了Unbounded Priority Inversion。
缺点
- PIP并不能解决死锁问题。
- PIP也不能解决阻塞传递的问题。
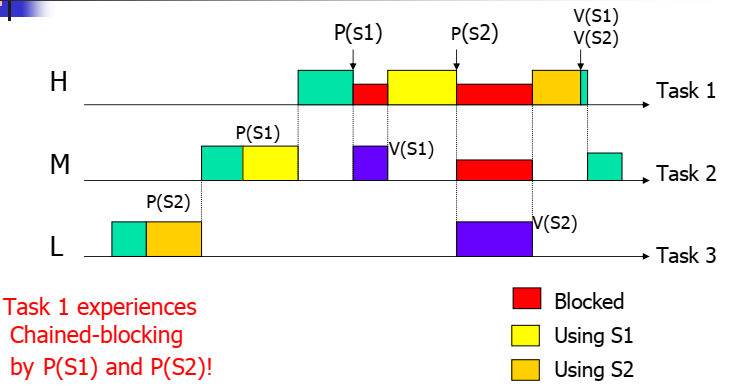
- PIP还有不够完善的地方是在处理多次资源请求时,每一次资源请求都可能被block,导致过多的context switch。如下的Task1。
PCP
PCP算法只能适用于binary semaphore场景。
定义
- 一个semaphore的ceiling是所有可能lock它的线程的最高优先级
- 某一时刻,针对某一任务J的ceiling是,除J以外的其他线程已lock的semaphore的ceiling最大值
- ceiling blocking: 因为优先级不大于系统优先级天花板导致的阻塞
- S∗: 导致ceiling blocking的信号量
- π(J): 任务J的优先级
- C(S): 信号量S的优先级天花板
- π(J): 系统针对J的优先级天花板
算法
- 当某一任务J需要lock一个semaphore时
- 若该资源已被J′ lock
- π(J)≤π(J′),则J被block
- π(J)>π(J′),则J′获得J的优先级,直到J′释放该资源
- 若该资源free
- π(J)≤π(J),则J被S∗阻塞,因为π(J)≤C(S∗),所以不会发生优先级继承
- π(J)>π(J),则J可以锁住该资源
- 若该资源已被J′ lock
- 如果一个任务不涉及申请资源,则它可以正常抢占(preempt)其他低优先级任务。
OCPP vs. ICPP
OCPP = Original Ceiling Priority Protocol, ICPP = Immediate Ceiling Priority Protocol
Wiki词条Priority ceiling protocol中提到这两种算法,OCPP就是Lui Sha et.在[3]中提到的算法。ICPP是OCPP的一个变种。在[5]中称之为Highest Locker’s Priority Protocol (HLP) 。Wiki上称:
The worst-case behaviour of the two ceiling schemes is identical from a scheduling view point. Both variants work by temporarily raising the priorities of tasks.
ICPP的基本算法是:
In ICPP, a task's priority is immediately raised when it locks a resource. The task's priority is set to the priority ceiling of the resource, thus no task that may lock the resource is able to get scheduled.
不明白后半句是啥意思,相同优先级的线程应该是可以得到轮转运行的,除非,禁止round robin
ICPP与OCPP的不同之处在于:
- ICPP is easier to implement than OCPP, as blocking relationships need not be monitored
- ICPP leads to fewer context switches as blocking is prior to first execution
- ICPP requires more priority movements as this happens with all resource usage
- OCPP changes priority only if an actual block has occurred
看起来ICPP唯一的问题是会带来频繁的调整优先级,OCPP只在发生blocking的时候调整
优点
- 因为PCP包含PIP,所以PCP包含PIP所有的优点
- PCP可以解决死锁问题。
证明
再看这张图
此时有:
C(S1)=H,C(S2)=H
当Task1试图执行P(S1)时,π(Task1)=C(S2)=H,显然π(Task1)≤π(Task1),不能获取S1,被阻塞,也就不会有后来的P(S2)了。
当Task2试图执行P(S2)时,π(Task2)=0,因为除了Task2,没有其他的资源被锁住。所以Task2可以顺利获得资源S1。
综上,死锁不可能发生。
- 没有阻塞传递。
证明
假设J3阻塞J2, J2阻塞J1
t3时,C(S1)≥π(J2)⋂C(S1)≥π(J3),J2 lock成功,说明π(J2)>C(S1),矛盾。正确的图如下:
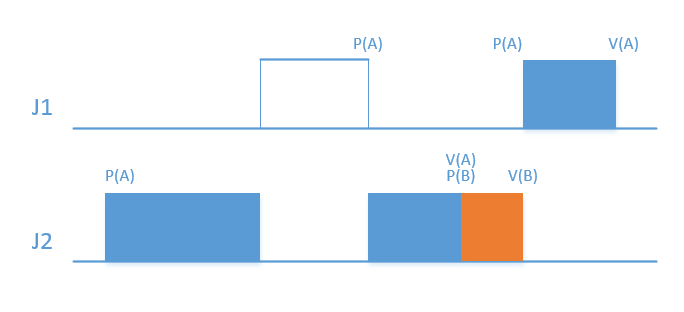
成功避免transitive blocking。
- 被低优先级任务阻塞(priority inversion)只会发生一次
证明
假设有π(J1)>π(J2)
- 如果J1被J2阻塞两次,分别在J1申请资源A,B时,则有
这种情况不可能发生,因为当A被释放时(V(A)),因为J1是高优先级任务,A一旦释放,J1则会立即得到运行
- 如果J1被不同的任务J2,J3阻塞
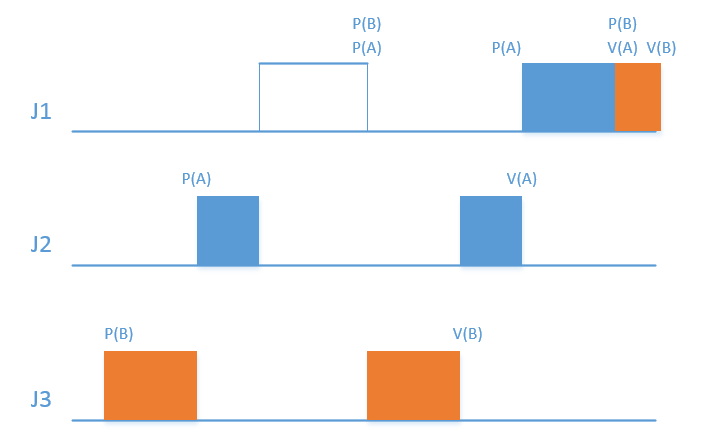
- J1对A,B有诉求,说明π(J1)≤C(A)⋂π(J1)≤C(B)
- J2能得到运行,说明π(J2)>π(J2)≥C(B)
- 综上,两者矛盾,因为π(J2)<π(J1)。所以如果J1对B有诉求,则J2在申请A的时候会被阻塞(ceiling blocking),因为π(J2)≥C(B)≥π(J1)>π(J2),即π(J2)<π(J2)
- PCP不用考虑PIP中的链式调整的问题
PIP中的链式调整如下图:
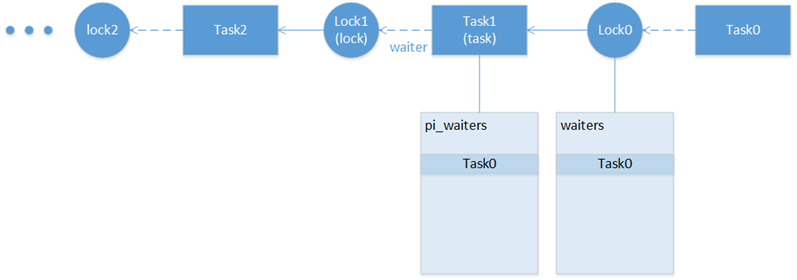
假如Task0对Lock0的申请,提升了Task1的优先级,则如果Task1已经因为申请Lock1,提升了Task2的优先级,则此时需要同步调整。但是在PCP中这一链条不存在。
考虑Task0来申请Lock0的时候,需要提升Task1的优先级,如果链条要成立则:
- π(Task0)>π(Task1)>π(Task2)>…
- owner(Lock1) = Task2, owner(Lock0) = Task1
- Task1 is in Lock1 waiter list
考虑下面两种情况:
- 当Task1要占住Lock0时,若Task2已经占住Lock1,则π(Task2)>C(Lock1),因为Task1对Lock1有诉求,则C(Lock1)≥pi(Task1),所以Task1无法锁住Lock0,该情况不成立,无法形成链
- 当Task1要占住Lock0时,若Task2尚未占住Lock1,
- 因为Task0对Lock0有诉求,说明C(Lock0)≥π(Task0),
- 因为Task1对Lock1有诉求,说明C(Lock1)≥π(Task1),
- 当Task2在申请Lock1,Task1已经占住Task0,此时Task2能获得Lock1,说明π(Task2)>C(Lock0)≥π(Task0),π(Task2)>π(Task0)说明链式调整不需要。
综上,PCP不用考虑链式调整。
缺点
PCP在绝大多数情况下都可以运行的很好了,缺点是:
- 只支持binary semaphore。缺少对多资源信号量的支持。
- 对动态优先级调度算法的实现过于复杂,要实时调整系统针对每个任务的priority ceiling。
- 虽然context switch已经叫PIP较为减少,但仍然有提升空间
SRP
SRP的产生可以克服这些PCP的缺点。
之所以叫stack based,因为它的诞生和嵌入式领域的stack sharing[1]有关。
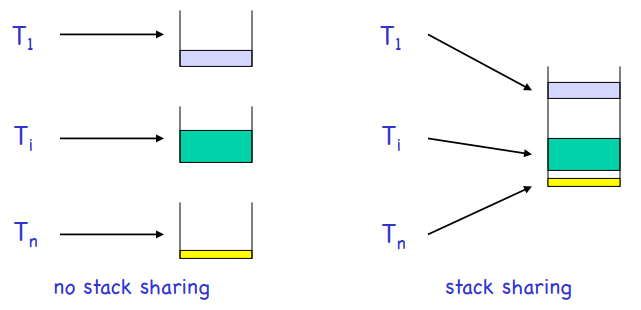
stack sharing用于节省内存。如果左边每个栈空间为10K,则总共需要30K。在栈空间不是很紧张的时候,采用stack sharing后,只需要总共10K的栈空间
stack sharing有一个特性,就是任务只能在栈顶的时候才能得到运行。当一个任务被另一个任务抢占后,意味着被抢占的任务要等到抢占者运行结束才有机会运行。
当采用stack sharing之后,stack也就变成了一种共享资源。
虽然SRP是因为stack sharing而产生,但即便在不是stack sharing的场合,也有很好的性能。
定义
preemption level
在[2][4]中都有提及如何定义preemption level,大意都是相同的。
[2]中提到
The reason for introducing preemption levels as distinct from priorities (p(J)) is to enable us to do static analysis of potential resource conflicts, even for some dynamic priority schemes such as EDF scheduling.
The only property of preemption levels on which these results do depend is the following condition (P1):
p(J)≤p(J′)⋃Arrival(J)≤Arrival(J′)⋃π(J)<π(J′)
[4]中提到
The general definition of preemption level used to prove all properties of the SRP requires that
if τa arrives after τb and τa has higher priority than τb, then τa must have a higher preemption level than τb
Under EDF scheduling, the previous condition is satisfied if preemption levels are ordered inversely with respect to the order of relative deadlines .
D(i)>D(j)⇒π(i)<π(j)
综上,总结如下:
- preemption level是一个抽象的数据,用来对资源竞争做静态分析。解决EDF框架中没有优先级数据的问题。
- preemption level在不同的调度框架下,实现方法可以不同,例如
- EDF,采用relative deadline的反比,即π(J)∝DJ1
- 其他调度框架,可以直接使用优先级数值
问题: 为什么在EDF下D(i)<D(j)能保证π(i)>π(j)?
证明:考虑下面两种情况:
- 若任务i先到,记作ti<tj,则ti+Di<tj+Dj,所以i的absolute deadline较小,i的优先级较高,且i先执行,j没有机会抢占i,所以π(i)>π(j)
- 若任务j先到,则考虑在SRP中,preemption只发生在任务开始时,所以j先到,j没有必要preempt,所以π(i)>π(j)
其他定义
-
priority:优先级,可能会动态调整,例如在一些动态优先级调度算法中,例如EDF
-
preemption level:相对优先级,preemption level是静态的,方便在动态优先级算法中,预测资源竞争。通常取任务的初始优先级。
-
ceiling:SRP的ceiling定义与PCP不一样。
⌈R⌉νR=max({0}⋃{π(J)∣νR<μR(J)})
其中:
- μR: maximum number of units of R that job J may need to hold at any one time.
- νR: the number of units of R that are currently available
- current ceiling: π=max{⌈Ri⌉νR∣i=1,…,m}
算法
因为preemption level是静态的,所以对ceiling的计算也是静态的,所以可以预先计算并写入一张表格。
引用原论文[2]中的例子
假如J1, J2, J3在生命周期中申请资源如下:

直观一点的资源申请图:
可以计算出⌈R⌉νR表格如下:
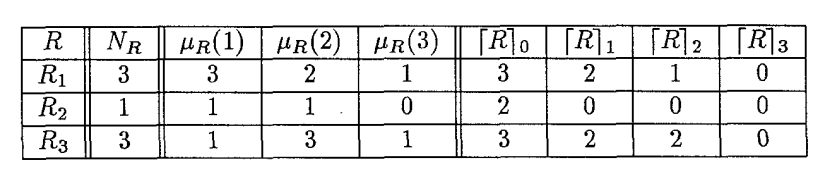
以⌈R2⌉0为例:
- νR=0
- ⌈R2⌉0=max({0}⋃{π(J)∣0<μR(J)})
- 若π(Ii)=p(Ji)=i , 则满足上式的最大的π(J)=2,如表所示。
- 当任务J ready时,计算此时的preemption level是否满足:π(J)>π,不满足则阻塞。
优点
- No job can be blocked after it starts. 没有block,所以没有额外的context switch。context switch只会发生在start execution和preemption。
- There can be n o transitive blocking or deadlock.
- If the oldest highest-priority job is blocked, it will become unblocked no later than the first instant that the currently executing job is not holding any non-preemptable resources
与PCP的异同
-
SRP与PCP相同的是,为了做统筹来得到全局最优解,二者都需要在系统初始化时决定每个资源的ceiling。
-
不同的是,两者评估线程重要程度的指标不同。PCP采用的是优先级,SRP采用的是抽象的preemption level。这导致两者的ceiling指标计算方法也不太一样。而且SRP因为采用的是抽象的preemption level,这在不同的调度策略下的含义也不一样,所以只能在同一种调度策略下参与统筹计算。
-
SRP对资源ceiling的计算方法,考虑了多资源,而PCP只能使用在二义锁的情况下。
-
因为SRP采用的是抽象的preemption level,所以可以很好的工作在类EDF调度策略下。而PCP如果要工作在EDF下,则比较困难。因为EDF的优先级由任务的绝对Deadline来决定,这与任务达到的时刻点有关系,如果要做PCP,就要知道线程的优先级,则要维护任务到达点信息,并计算优先级。
-
SRP因为他算法的优势,还带来了一些其他的优点,例如:
- 线程一旦开始,就不会因为资源而被block,这使得上下文切换次数可以减少到最少。
- 相比PCP,SRP更易于实现。
参考文献
[1] Bhuvan Middha, Matthew Simpson and Rajeev Barua, "MTSS: Multi Task Stack Sharing for Embedded Systems ", Department of Electrical & Computer Engineering University of Maryland College Park
[2] T.P. Baker, "A Stack-Based Resource Allocation Policy for Realtime Processes ", In Proceedings of the Real-Time Systems Symposium, pages 191–200, 1990
[3] Lui Sha; Ragunathan Rajkumar & John P. Lehoczky (September 1990). "Priority Inheritance Protocols: An Approach to Real-Time Synchronization". IEEE Transactions on Computers.
[4] The 2011 book Hard Real-Time Computing Systems: Predictable Scheduling Algorithms and Applications by Giorgio C. Buttazzo featured a dedicated section to reviewing SRP from Baker 1991 work.
[5] "Resource Access Protocols" slides from UPPSALA UNIVERSITET
PIP在Linux+glibc中的实现
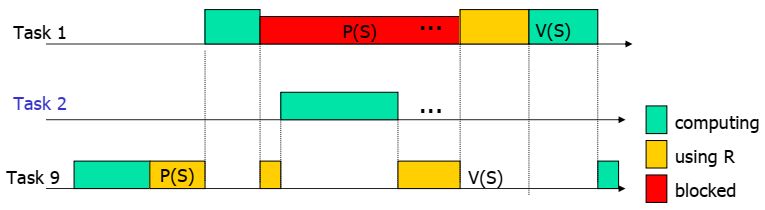
优先级反转
优先级反转指一个高优先级任务因为资源被低优先级任务占用,而不得不等待。这个逻辑本身没有什么问题。优先级反转带来最直接的问题就是高优先级可能因为这次阻塞,而无法确定阻塞时延。如下图所示。
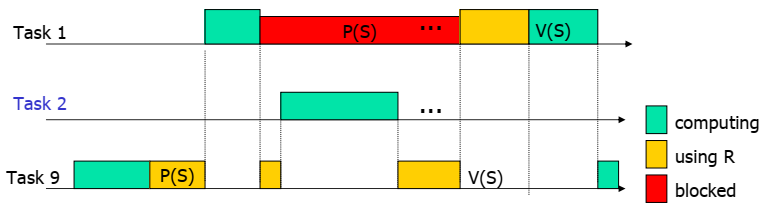
Task 9优先级较低,所以很容易被其他优先级的任务抢占运行,导致对资源S的锁无法释放,而高优先级的任务因为要持有该锁,不得不等待。
优先级继承
Priority Inheritance Protocol翻译为优先级继承,简称PIP。这是解决上述Unbounded inversion最直接的办法,就是将占有锁的线程优先级调整到在等待的任务的最高值。这个算法是贪婪的,局部最优,但不是整体最优解,在此之上又有PCP(优先级天花板)和SRP(基于栈的资源策略)。本文不做讨论。本文主要从源码的角度,阐述PIP在Linux和glibc中的具体实现。
Overview
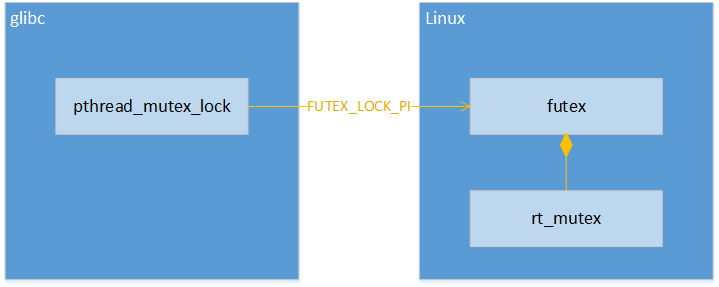
Linux下的PIP实现分成以上3个部分:
- glibc中的pthread_mutex_lock提供用户接口,通过FUTEX_LOCK_PI实现优先级调整
- Linux的futex部分提供FUTEX_LOCK_PI的实现
- 最终的锁机制通过rt_mutex来实现
pthread_mutex
Types
pthread mutex是POSIX pthread库中定义的一种锁机制,与信号量不同的是,这个锁只有两种状态:locked或unlocked。与binary semaphore不同的是,mutex只能被lock的线程unlock,即只能被mutex owner unlock。
目前POSIX标准(1003.1-2008)中定义了4种类型的mutex:
- PTHREAD_MUTEX_NORMAL
- PTHREAD_MUTEX_ERRORCHECK
- PTHREAD_MUTEX_RECURSIVE
- PTHREAD_MUTEX_DEFAULT
这4种mutex不同之处如下
| attempting to relock this mutex without first unlocking | Attempting to unlock a mutex locked by a different thread | |
|---|---|---|
| NORMAL | deadlock | undefined |
| ERRORCHECK | return error -EDEADLOCK | return error |
| RECURSIVE | succeed in locking | return error |
| DEFAULT | undefined | undefined |
glibc对上述4种类型的mutex进行了扩展,例如:
case PTHREAD_MUTEX_PI_RECURSIVE_NP:
case PTHREAD_MUTEX_PI_ERRORCHECK_NP:
case PTHREAD_MUTEX_PI_NORMAL_NP:
case PTHREAD_MUTEX_PI_ADAPTIVE_NP:
case PTHREAD_MUTEX_PI_ROBUST_RECURSIVE_NP:
case PTHREAD_MUTEX_PI_ROBUST_ERRORCHECK_NP:
case PTHREAD_MUTEX_PI_ROBUST_NORMAL_NP:
case PTHREAD_MUTEX_PI_ROBUST_ADAPTIVE_NP:
主要多了这3种属性:
-
ADAPTIVE:在SMP架构下,并不直接进入wait,而是先调用spinlock等待一小段时间。musl里默认都采用了这种实现
-
PI:包含该属性的mutex,实现了优先级继承(Priority Inheritance, PI)
-
ROBUST:若线程退出时未释放锁,则以后对该锁操作都会返回-EOWNERDEAD,与之对应的是PTHREAD_MUTEX_STALLED(这是默认配置),对该异常锁的操作会出现undefined行为。
再与原先的4种属性进行排列组合。
"_NP" suffix
Note: the _NP suffix indicates a non-portable extension to the POSIX specification. In fact the latest specification, 1003.1-2008 [2], includes most of the Linux additions so you can leave the _NP ending off. I have chosen not to because some older versions of the header files only have the _NP variants.
根据最新的POSIX标准1003.1-2008,这些扩展并没有加入。
本文只关注MUTEX_PI实现。
PTHREAD_MUTEX_PI
pthread_mutex_lock
重要数据结构如下:
typedef union
{
struct __pthread_mutex_s __data;
char __size[__SIZEOF_PTHREAD_MUTEX_T];
long int __align;
} pthread_mutex_t;
struct __pthread_mutex_s
{
int __lock __LOCK_ALIGNMENT;
unsigned int __count;
int __owner;
...
}
如果不考虑ROBUST情况的处理,一次针对实现了PI属性的pthread_mutex_lock操作如下:

atomic_compare_and_exchange_val_acq
这是一种原子操作,先比较再赋值,伪代码如下:
int compare_and_swap(int* reg, int oldval, int newval) { ATOMIC(); int old_reg_val = *reg; if (old_reg_val == oldval) *reg = newval; END_ATOMIC(); return old_reg_val; }针对代码中的具体情况:
oldval == 0: 表示mutex->__data.__lock == 0,即该lock无owner,可以获得。oldval != 0: 表示该mutex被lock了,从而进入kernel来处理锁的情况。
pthread_mutex_lock的逻辑比较简单,就是通过一个原子操作判断锁是否已经被锁住。如果没锁住就更新owner,以及user计数。如果已经被锁住,则陷入内核调用FUTEX_LOCK_PI系统调用完成上锁的操作。
pthread_mutex_unlock
这个接口基本上就是直接调用futex_unlock_pi SYSCALL来完成工作:
/* Unlock the mutex using a CAS unless there are futex waiters or our
› TID is not the value of __lock anymore, in which case we let the
› kernel take care of the situation. Use release MO in the CAS to
› synchronize with acquire MO in lock acquisitions. */
int l = atomic_load_relaxed (&mutex->__data.__lock);
do
› {
› if (((l & FUTEX_WAITERS) != 0)
› || (l != THREAD_GETMEM (THREAD_SELF, tid)))
› {
› INTERNAL_SYSCALL_DECL (__err);
› INTERNAL_SYSCALL (futex, __err, 2, &mutex->__data.__lock,
› › › › __lll_private_flag (FUTEX_UNLOCK_PI, private));
› break;
› }
› }
while (!atomic_compare_exchange_weak_release (&mutex->__data.__lock,
› › › › › › &l, 0));
futex
futex是一种内核的等待机制,等待某个用户态数据被设置成某个值。针对优先级继承的futex略有不同。它不再等待用户传入的地址上的值,而是基于内核rt_mutex机制实现等待,上锁和解锁的功能。看下面glibc和Linux的接口对接:
// glibc: pthread_mutex_lock.c
int e = INTERNAL_SYSCALL (futex, __err, 4, &mutex->__data.__lock,
› › __lll_private_flag (FUTEX_LOCK_PI,
› › › › › private), 1, 0);
// Linux: futex.c
long do_futex(u32 __user *uaddr, int op, u32 val, ktime_t *timeout,
› › u32 __user *uaddr2, u32 val2, u32 val3)
{
...
case FUTEX_LOCK_PI:
› return futex_lock_pi(uaddr, flags, NULL, 1);
...
}
可见:
uaddr = &mutex->__data.__lockflags = __lll_private_flag (FUTEX_LOCK_PI, private)val = 1, timeout = NULL
关于lock/unlock的叙述会简化掉time相关部分,以及PI无关的ROBUST等特性。
重要数据结构
/*
* Hash buckets are shared by all the futex_keys that hash to the same
* location. Each key may have multiple futex_q structures, one for each task
* waiting on a futex.
*/
struct futex_hash_bucket {
› atomic_t waiters;
› spinlock_t lock;
› struct plist_head chain;
} ____cacheline_aligned_in_smp;
/**
* struct futex_q - The hashed futex queue entry, one per waiting task
* @list:› › priority-sorted list of tasks waiting on this futex
* @task:› › the task waiting on the futex
* @lock_ptr:› › the hash bucket lock
* @key:› › the key the futex is hashed on
* @pi_state:› › optional priority inheritance state
* @rt_waiter:› › rt_waiter storage for use with requeue_pi
* @requeue_pi_key:›the requeue_pi target futex key
* @bitset:›› bitset for the optional bitmasked wakeup
*
* We use this hashed waitqueue, instead of a normal wait_queue_entry_t, so
* we can wake only the relevant ones (hashed queues may be shared).
*
* A futex_q has a woken state, just like tasks have TASK_RUNNING.
* It is considered woken when plist_node_empty(&q->list) || q->lock_ptr == 0.
* The order of wakeup is always to make the first condition true, then
* the second.
*
* PI futexes are typically woken before they are removed from the hash list via
* the rt_mutex code. See unqueue_me_pi().
*/
struct futex_q {
› struct plist_node list;
› struct task_struct *task;
› spinlock_t *lock_ptr;
› union futex_key key;
› struct futex_pi_state *pi_state;
› struct rt_mutex_waiter *rt_waiter;
› union futex_key *requeue_pi_key;
› u32 bitset;
} __randomize_layout;
/*
* Priority Inheritance state:
*/
struct futex_pi_state {
› /*
› * list of 'owned' pi_state instances - these have to be
› * cleaned up in do_exit() if the task exits prematurely:
› */
› struct list_head list;
› /*
› * The PI object:
› */
› struct rt_mutex pi_mutex;
› struct task_struct *owner;
› atomic_t refcount;
› union futex_key key;
} __randomize_layout;
futex_hash_bucket对应一个用户态的uaddr。通过用户态传入的uaddr地址,来获得对应的futex结构体。用hash的原因是传入的是uaddr地址值,数字很大,分布很散,所以用hash可以有效索引。
futex_q是一个临时变量,对应了一个futex的waiter线程。它通常被用来传递各种数据结构。
pi_state是task_struct内部的一个变量,在futex_lock_pi调用refill_pi_state_cache里面做分配。
static int refill_pi_state_cache(void)
{
...
pi_state = kzalloc(sizeof(*pi_state), GFP_KERNEL);
current->pi_state_cache = pi_state;
...
}
futex_lock_pi
这个函数的逻辑还是比较直线的,同大多数锁的实现一样,先尝试原子锁,如果不行,则调用rt_mutex的实现来处理优先级继承的机制。以下捡取比较重要的函数做阐述,也可以参考参考文献[3], [4]中的描述。
queue_lock, queue_unlock
对hash_bucket进行锁操作。他们操作的是hash_bucket下的lock,同时也是futex_q下的lock_ptr。这里锁的出现比较混乱,有时调用上面的这两个函数,有时直接对lock指针操作。需要小心。
__queue_me, unqueue_me
这里将申请futex的线程在hash_bucket的chain上做添加或移除操作。还会涉及锁的操作。
以上4个函数更多的与futex的实现相关,与优先级继承并无关系,所以可以略过。
futex_lock_pi_atomic

这个函数做的就是原子操作来请求锁,
- 如果futex没有waiter,则直接获得锁并返回1,表示成功获得锁
- 如果有waiter,就返回0,表示ready to wait
这个函数不同的是会做一些与PI相关的处理:
- 有waiter的情况:
- 调用attach_to_pi_state来获得该top_waiter的pi_state
- 没有waiter的情况
- 调用attach_to_pi_owner来取用本线程里分配的pi_state结构体,并更新数据。之后,会被queue到hash_bucket的队列中。
rt_mutex接口
futex_lock_pi中使用到如下这些rt_mutex接口:
- rt_mutex_init_waiter:初始化waiter数据结构,其实为一个红黑树的节点。这个waiter对应当前线程,并反映线程在某个锁上的等待关系。
- __rt_mutex_start_proxy_lock:这个是PI的核心函数,用来对各waiters数据进行操作,以及遍历lock链来检查死锁。这个函数与之前的原子检查类似,如果返回1表示已经获得锁,如果返回0,则ready to wait。
- rt_mutex_wait_proxy_lock:通过__rt_mutex_start_proxy_lock处理之后,如果还没有获得锁,那就可以开始等待了,这个函数将线程切换为TASK_INTERRUPTIBLE状态,并开始等待。这其间会处理基于时间的等待,且会触发调度。
- rt_mutex_cleanup_proxy_lock:现在已经阻塞结束了,如果还没获得锁,要么是超时,要么是出错,总之要将本线程从waiters中移除,这个函数就是起这个作用。
fixup_owner
从注释上看,是为了处理lock steal。而lock steal似乎多发生在futex requeue操作上,目前尚未仔细研究。
futex_unlock_pi
futex_unlock_pi释放futex以及更新相应的pi_state和rt_mutex的owner字段。函数调用层次比较深,基本上都是每一层做一些基本的更新工作,最终调用到__rt_mutex_futex_unlock来重新调整本线程的优先级,并将top waiter放到wake queue上。在rt_mutex_postunlock调用的rt_mutex_postunlock将新线程唤醒。
如果没有waiter,则使用cmpxchg_futex_value_locked来将用户态地址uaddr上的值设为0。因为锁没有waiter了,所以优先级也不需要恢复了,或者已经恢复过了。
如果有waiter,就使用下面几个函数来切换lock owner,并恢复优先级继承的优先级。
wake_futex_pi
这个函数做了下面几件事:
- 用cmpxchg_futex_value_locked将用户态传入的uaddr处的数值更新为新的
rt_mutex_next_owner() | FUTEX_WAITERS list_del_init(&pi_state->list):将list从原先的表上删除,并重新初始化,准备移到其他的表上。list_add(&pi_state->list, &new_owner->pi_state_list)pi_state->owner = new_owner__rt_mutex_futex_unlockrt_mutex_postunlock
mark_wakeup_next_waiter
注意:此时pi_state->owner已经设置过了,但是pi_state->pi_mutex->owner还没有设置。这个函数主要做了下面几件事情:
rt_mutex_dequeue_pi(current, waiter);rt_mutex_adjust_prio(current):在这里调整了当前线程的优先级,完成了整个优先级继承协议。wake_q_add(wake_q, waiter->task)
put_pi_state
这个函数更多的是清理工作:
- 调用了
rt_mutex_proxy_unlock来释放pi_state->pi_mutex. - 释放了current->pi_state_cache空间
cmpxchg_futex_value_locked原子操作
static int cmpxchg_futex_value_locked(u32 *uval, u32 __user *uaddr, › › › › u32 oldval, u32 newval) { ATOMIC(); int val = *uaddr; if (val == oldval) { *uaddr = newval; } *uval = val; END_ATOMIC(); return 0; } 其中ATOMIC操作通过page_disable()和preempt_disable()保证。
__rt_mutex_start_proxy_lock
从上面futex_lock_pi用到的rt_mutex接口介绍中可知,这个函数是整个PI处理的核心,这个函数又主要调用task_blocks_on_rt_mutex来处理PI。
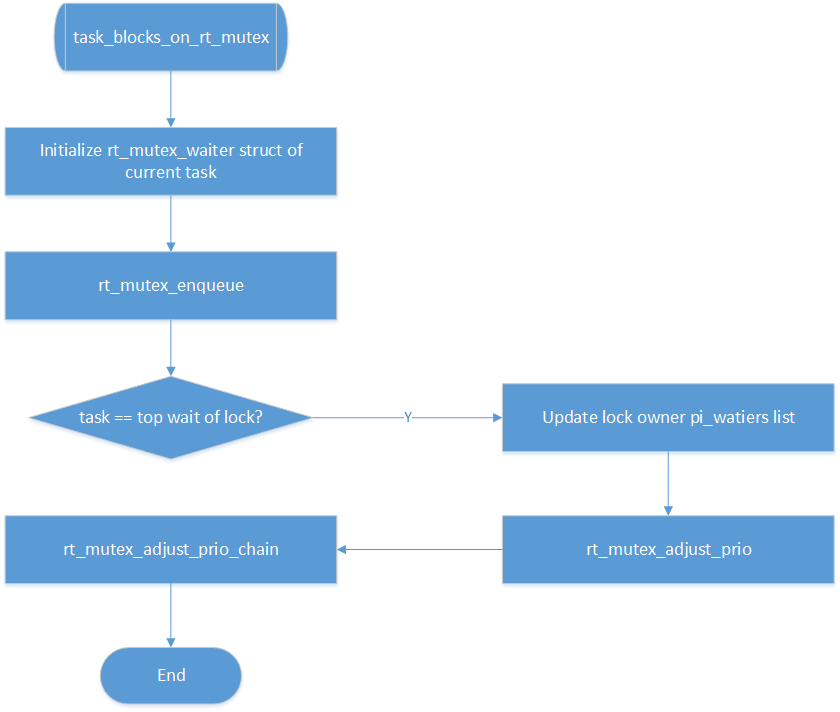
rt_mutex_adjust_prio(owner)
这个函数就是调整阻塞线程的优先级,从而实现优先级继承的。实现方式也很简单:
if (task_has_pi_waiters(p))
› pi_task = task_top_pi_waiter(p)->task;
rt_mutex_setprio(p, pi_task);
把owner线程设置为owner线程所有waiter(可能来自多个锁)的最高优先级。
rt_mutex_adjust_prio_chain
为什么有这个链式调整?
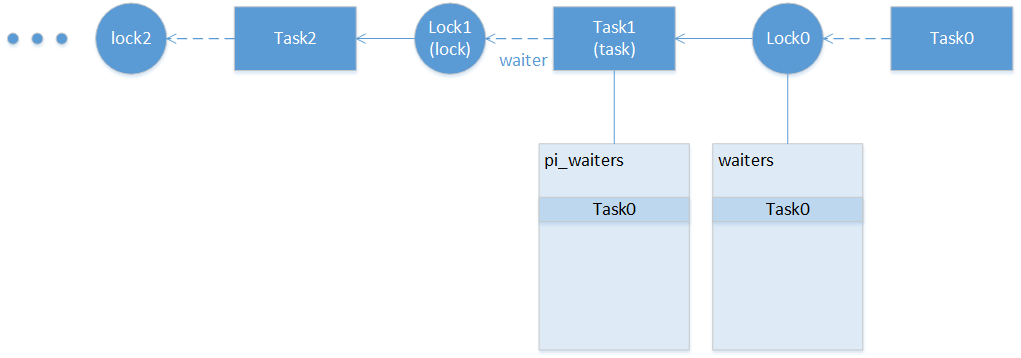
这里有两张表格:
-
每个rt_mutex有张waiters表格,表示所有等待的线程
-
每个task也有张表格,表格里的每一项对应owner线程占有的锁,每一项是一个rt_mutex_waiter,表示申请该锁的最高优先级waiter
假设Task1就是owner,Task0对Lock0的申请导致Task1提升优先级,如果Task1同时被Task2持有的某个锁阻塞,则Task1优先级的改变,有可能会导致Task2 pi_waiters列表改变,同时可能导致Task2优先级改变。依此类推,就会导致上面的这种链式反应。
链处理流程
整个chain的处理流程大致如下:
- 如果Task0是Lock0的top waiter,则激发该链式调整。
- 因为Task0成为Lock0的topwaiter,则Task1的pi_waiters需要调整,则Task1的优先级可能需要调整。退出可能:
-
起点锁释放了
-
链的当前环节被更改( next_lock ≠waiter->lock)
-
Task1没有占锁
-
- 如果Task1也wait在某个lock的时候,则该lock的waiters需要调整,这里有若干种退出可能。
- Task1没有被block
- Task1 pi_waiters中有优先级高于Task0的waiter,换句话说,lock0的top_waiter不是Task1的top pi_waiter,优先级继承不需要继续传递
- 如果Task1在申请Lock1 的时候的优先级(这个记录在waiter->prio里)与当前调整后的优先级相等,则后续没必要在继续调整优先级
- 检测到DEADLOCK
- 回到1继续执行,直到退出链式处理
死锁
有3种情况,函数会返回死锁
- 链上超过1024个锁节点
- 链上任意Task节点申请第一个锁节点,即Lock0
- 链上任意一个锁owner是第一个Task节点,即Task0
参考文献
[1] [Mutex mutandis: understanding mutex types and attributes]. (http://2net.co.uk/tutorial/mutex_mutandis)
[2] POSIX Revision of IEEE Std 1003.1-2008
[3] Source code analysis of pthread_mutex_lock
[4] linux pi_futex浅析
[5] Linux 4.20-rc3 source code
[6] glibc 2.28 source code
如何规划职业的未来
不管是刚毕业的菜鸟,还是像我这样工作了快10年的老油条,作为一个职场人,内心都会有一个终极拷问: 我到底要成为什么样的人?说专业一点就是职业生涯的规划。
这两天还看到阮一峰博客上的推送,关于乔布斯的热情假说,以及他的反调《优秀到无法忽略》(《So Good They Can't Ignore You》)。下面大段引用博文中,关于两个论点的阐述。
2005年,斯坦福大学邀请乔布斯在毕业典礼演讲。这个演讲后来成为经典,《乔布斯传》说"或许有些演讲对后世影响更大,但是你找不到(比这篇)更好的演讲。"
演讲中,乔布斯说了一段有名的话。
"你们的时间有限,所以不要把它浪费在过其他人的生活。最重要的是,你要有勇气跟随你的内心和直觉。某种程度上,它们已经知道你真正想要成为什么样子。其他所有事情都是次要的。"
这段话后来被称为"热情假设",很多人都引用它鼓励年轻人:寻找职业方向的时候,要跟随内心的热情(passion),去做那些你有强烈意愿从事的工作。
但是,美国最近出版了一本新书《优秀到无法忽略》(《So Good They Can't Ignore You》),声称乔布斯的这个建议是完全错误的,误导年轻人。别的不说,乔布斯本人也不遵守"热情假设"。年轻时,他对禅宗思想最感兴趣,去印度学习佛教。如果他真的追随自己的内心,他就应该去当一个禅宗老师,而不是跑回美国创办苹果公司。这本书认为,以下几个原因导致"热情假设"不是一个好的建议。
第一,热情真的很罕见。大部分人都对自己的工作没兴趣,而是对某种爱好(比如打球、钓鱼)有兴趣。如果大部分人都找不到自己的职业热情,你怎么能叫他们去追随热情呢?
第二,热情需要时间来建立。许多人刚开始工作的时候,对自己的职业并没有兴趣,随着时间积累,他们的经验越来越多,能够掌控的东西越来越多,这才慢慢开始热爱自己的工作。找工作阶段,你可能根本不会意识到这个职业就是你的热情所在。
第三,过度强调热情,容易对现状产生不满。2010年的一项调查发现,只有45%的美国人对自己的工作满意。由于很多人相信,无法产生热情的工作不是好工作,导致对职业生涯抱有不切实际的期望,对现有的工作不满意,不断跳槽。
这本书提出,热情不是凭空产生的,它跟自主权有关。如果你在某个职位上的自主权越大,能够掌控的东西越多,就越容易对当前的职业产生热情。与其强调跟随内心的热情,不如强调如何在某种职业里面获得自主权。你必须使自己变得优秀,让别人无法忽视你,同意让你掌控更多的资源,这就是书名的含义。
在这之前,我并没有听过、看过或读过乔布斯的演讲以及《乔布斯传》。因为这篇博文和想写的这篇文章,我特意去读了乔布斯的演讲稿。关于乔布斯的观点,我不能同意更多。一个人想要在一件事情上成功,靠的不应当是外部的条条框框,或者是各式各样,形形色色的毒鸡汤。所有的动力,应该来自于你的内心。做这件事本身提供给你的快乐,才能激励你持续的坚持下去,持续地去付出。因为他持续的用快乐来回馈,你才不会计较付出的多寡。这样的回报才会丰厚,因为你付出的多。而外部的一切因素,或是激励,或是刺激都是不稳定的,都是易变的。今天流行这个,明天流行那个;曾经互联网火,现在AI火;今天听要保持热情要奋斗,心里像打了鸡血,不破楼兰死不还,明天听个于丹的黄老之学,又要反思,我这么拼是为了谁,人生而不就是为了快乐吗,还是岁月静好吧。问问自己,是不是经常有这样的心理波动?如果试想,你每一个都去追随,那是不是事事都是浅尝辄止呢?
其实世事也并没有那么复杂。人,作为一种动物,总会去追逐让你得到快感的事情。比如,吃,有多少人发誓要减肥,但转脸就忍不住,因为美食在你的潜意识里代表了美好。例如夫妻,为什么曾经如胶似漆,现在却房事冷淡,因为你们曾经努力地去营造美好,后来平淡之后,一定是有了没那么美妙的一次或几次,夫妻之事在潜意识已经不代表快乐。再举一个不恰当的例子,一个瘾君子他不知道毒品的危害吗?为什么还有人把自己往万劫不复的深渊推?因为那是来自心底的对那份快感的追求。
所以内心的热情,或者愉悦的感觉,才是稳定的动力之源。上升到哲学的角度, 不是说内因才永远是主导因素吗?我们虽然没法像瘾君子那样歇斯底里地追求我们的梦想,但我们至少可以有意识地寻找那份原始而简单的快乐。
再说为什么乔布斯没去做禅宗老师。因为世事都是动态的。你可能某时某刻对某一件事物特别痴迷,但随着你的成长与认识的深刻,你可能并不能发现它能持续地给你快乐。更多的只是一时的刺激。这里所谓的爱好,应当是能一直吸引你走出心理舒适区的东西。所以,看电影,上网这种就不能算是爱好了。这也是为什么很多人喜欢打球,钓鱼,却不能将它们变为职业的原因。因为它们带来的快乐更多的是感官上的刺激,或是心里放松带来的轻松舒适,但它们不足以让你迈出心理舒适区。你喜欢打篮球,那你能做到每天练1000次投篮吗?我想你做不到,你逼自己做一次也不会快乐,但科比就能做到,而且十几年如一日,乐此不疲。你觉得是有什么在激励他吗?对篮球的热爱,这就是那份最原始的快乐。别说篮球,钓鱼不能做职业,大把人以此为生。乔布斯在印度学习期间,可能也认清了自己,他并不那么热爱禅宗。
然后,我认为这本《优秀到无法忽略》就是一碗满满的毒鸡汤。热情确实很罕见,这也是为什么各行各业真正优秀的人都只是凤毛鳞角。但这并不代表我们不必追逐优秀。尤其在中国的教育环境下,这点尤其重要。因为从小到大,都活在别人的眼中。所有的决定都是把我们塑造成父母想让我们成为的人。做的一切努力都是为了成为老师眼中的好学生。从来都没有人真的在乎我们喜欢什么,擅长什么。不要告诉我什么干一行爱一行。爱不是不讨厌。说不讨厌的,多半是不爱。爱是需要你能感受到那一份快乐,能不断激发自己去突破自己的。如果你只是因为不讨厌,而努力压制自己的热情,这妨碍了你的快乐,也阻挡了你成为更优秀的人。
热情的建立确实需要时间。但我认为并不是因为掌控的东西越来越多才导致热情。而是在越来越多的历练中,发现自己,探索自己,到底喜欢什并且擅长什么,并最终以此作为长期的职业目标。刚毕业的时候,我们没有任何工作的经历,很多事情靠想象。但很多事情只有经历了才能给出恰当的评断。所以千万不要以我觉得我喜欢什么,或者我不讨厌什么来作评判热情的标准。选择一项事情,就要全身性的投入,这样才能在过程中不断的了解自己。否则任何事情都浅尝辄止,也并不会对认知自己带来更大的帮助,相反却浪费了宝贵的时间。我认为每一次尝试的时间至少以年为单位。通常一个本科生22岁毕业,到30岁有8年的时间,硕士生有5~6年。抓住这几年的时间,后面再想尝试,你的机会成本会更高。当发现自己确实缺乏热情的时候,也要尽快的抓住尝试新方向的机会。这也很重要,尤其对中国教育出来的孩子。记住现在你要为你自己的职业生涯负责,没有人再帮你做决定,分担责任。你要对你自己负责。回想自己当初刚毕业时,很多同学都做技术,现在看看,有做投资的,做产品经理的,做老师的…刚毕业的时候入对行,确实很重要,但我认为更重要的是你对自己的探索,对自己认识的提高,才能真正的帮助你在未来30多年的职业生涯中更好的追求自己的热情,做自己喜欢做的事,从而把自己变为更优秀的人。
所谓人生不如意者,十之八九。通常我们用这句话来比喻人生的艰辛。其实,这何尝不是正好说明着职场的现状呢?有多少人真正爱着你现在的工作呢?这不正说明了为什么优秀的人这么稀少的缘故吗?优秀的人和成功的事业从来都是相辅相成,互相成就的。所谓天生我材必有用。这不是一句敷衍的安慰的话。每个人都有自己真正热爱的事情,只是你没有认识到,也没有投入去寻找。有的人运气好,正好从事了自己有热情的事情,所以成功了;有的人认识到热情假设,并用心去寻找,但是总是缘悭一面,但他们还在路上;但大多数人,并没有意识到热情的存在,他们浑浑噩噩得过且过,抱怨自己的每一天,却不去寻找,或者不知道如何寻找。我理解最后一种人的想法,因为世事繁杂,需要你有一双慧眼和一颗善于思考的心。这其实也是一种天分啊,和能够戒躁戒躁的努力一样,他也是一种天分,可能是可遇而不可求的。但如果我写这些能够激起你内心哪怕一丝丝的波澜,却也真是无量功德一件。因为一旦你开始思考,上路,你就能引领你走向寻找热情,成为优秀的人的路。哪怕是第二种人,总好过浑浑噩噩过完这30多年。
说了这么多,只是从我自己的角度和经历来附和乔布斯的热情假说。做自己“喜欢”做的事情真的真的很重要。但前提是你要能理解“喜欢”是什么。想想你追求过的女孩儿吧,我觉得这样的感觉没什么两样。
如何做到不被年轻人取代
这是我最想写的一个话题,因为我觉得这也是最多人在思考答案的一个问题,尤其是像我这样面临35岁危机的人。自己思考了很多,也听到别人的经验之谈,在各种面试受挫时,也反思很多次。其中有些许心得,不论对错,与君分享。
假如有这样一天,你在一个公司工作了很多年(因为本人经历有限,就还以我最熟悉的科技公司为例),来了一个刚工作2,3年的小伙子。你俩都是程序员,你觉得自己的优势,劣势在哪儿呢?
劣势,我们好像能说一大堆:
- 精力不行了,要兼顾家庭,言下之意,不利于加班
- 技术落伍了,不能接受新事物
- 潜力不足,言下之意,不再愿意学习来提升自己。
优势,看起来只有一条,经验。
所谓知己知彼,百战不殆。我们如何发挥自己的优势,弥补自己的劣势,才能打赢这场职场之战。
经验到底重要吗?在如今技术变革如此快的今天,我们掌握的那些老掉牙的技术真的重要吗?Of course,当然。一个高效程序员的效率可以是普通程序员的10倍,甚至100倍。你在成长路上踏过的每一个坑,都帮助你离高效程序员更近一步。他即便已经有一些经验了(2~3年),但他踩过的技术上的坑一定没你多,你一定更接近软件编程的本质。同时,本行业的积累也是很重要的。编程这一技能,跨行业是有效的,但领域知识不行。做互联网大数据的,一定没有踩过造汽车的坑。而领域知识确实需要大量的项目经验和时间来沉淀。
拥有经验就能赢了吗?答案当然是错错错。我们的先辈告诉我们,不能躺在历史的功劳簿上。经验只能代表你当前的状态。从公司的角度看,你的经验多一些,代表你当前的能力比那位小鲜肉强一些。只能说明你的起跑线比别人靠前一些。这些经验,这位小鲜肉同学只要勤奋努力,加上资质尚可,追回来分分钟的事情。打个不恰当的比方,你跟博尔特比赛跑,你起跑线提前个10米,有毛用。
如果不想被年轻人超越,你必需拥有只依靠原始积累无法得到的品质。好比古代的战争。兵力是一个很重要的因素,有时候靠人多就能赢。征兵只要君主肯出钱,横征暴敛,抓壮丁,人总是能凑出来的。但更多的时候,战争还是仰仗优秀的指挥官和杰出的军事家。君不见历史上多少以少胜多,以弱胜强的战例。正所谓千军易得,一将难求。工作亦是如此,经验的积累,依靠时间的沉淀,精力的付出总可以做得到的。但何为将才,换句话说,什么才是我们的核心竞争力?什么才能筑成围护职场的深沟大壑?我总结如下:
- 首要的是三观,世界观,人生观,价值观
- 良好的自省与自控能力,良好的生活习惯
- 能客观理智地对待人与事物,凡事保持正向思维
- 与人沟通的能力
- 有自己的爱好,有对文学或艺术的鉴赏能力
经验是技术层面的,是兵力,是你的筹码。如何持续地提升自己,如何运用好你的筹码来构建出色的团队攻城拔寨。这些从长远看,我认为比技术本身,或经验本身更重要。毕竟技术(经验)是死的,它不能帮你完成项目,做出产品。人才是活的,怎么提升自己,整合资源,才能帮你做出好的项目,好的产品。所以这些软技能才是真正的核心竞争力应。而且所有的这些软技能都不是靠一天两天,甚至一年两年的速成可以做到的。他需要思考、总结、顿悟,有意识地训练自己。
世界观,人生观,价值观
所谓三观不正,何以正天下。我理解的三观:
- 世界观:每个人的社会地位不同, 认知不同,观察问题的角度也不同,造成的观念或观点的差别。例如:你总能看到一件事的好处和坏处吗?你总能理解一件事除了好和坏,它其实总是处于一个动态的中间态吗?人说众生平等,你真的能做到吗?
- 人生观: 人活一世,到底什么才是你想要的生活。你辛苦工作到底是为了谁?是钱重要,是快乐重要,是家庭重要,还是成就感重要?直击内心吗?想清楚了吗?
- 价值观: 什么是对你有价值的?钱吗?未来的发展?老板安排你做一件琐碎的事,你能看到对你有价值的部分吗?
拥有比较好的三观,才能更容易摆正自己的心态,明确自己前进的方向,理性而平和地对待身边的人和事,积极正向地去生活。
三观的形成有诸多因素--原生家庭,教育,阅历等等。一个人的三观同时也是不断变化着。你读过的每一本书,每一篇文章都在无形之中影响着你。但内因总是主导因素,作为一个成年人,别人已经很难教会你什么。自己多思考,多求证,才会成长。
有自己的爱好,有对文学或艺术的鉴赏能力
有自己的爱好是一件很好的事情。我们的世界本来就是复杂的。他不是只由一堆逻辑与数据搭建起来的,那是游戏,是虚拟世界。现实世界要复杂得多。在编程之外,如果有自己的爱好,例如艺术,摄影,音乐舞蹈,亦或是花鸟虫鱼,体育运动,都可以帮助你从不同维度去理解世界,去认识你自己。从而帮助你树立或修正你的三观。人们常说的陶冶情操,大抵如此。另一方面,做你爱做的事的时候,身心必是愉悦的,这样能更好地在工作之余放松自己,释放压力,再工作的时候会更理智,更专注。效率自然就高了。记得上学的时候,老师经常提起这样一种人,整天在玩,考试总能名列前茅。现在想来这些人除了智商高,爱好和工作的关系一定也处理得很好。
自省与自控能力
这个说起来容易,做起来真的很难。需要大家用心去体会。何为自省?孔子曰,吾日三省吾身。华为的核心价值观有,坚持自我批判。这就是自省。当发生问题时,人们会本能地认为都是别人的责任。因为你对自己的了解一定胜过对别人的了解。因为不了解而怀疑,进而有意无意的甩锅。在甩的时候,即便在甩之后,能不能即时地认识到自己的问题?此为自省。
自控是你能对抗你的欲望吗?当你在做蕃茄钟的时候,能克制自己不玩手机吗?在编程的时候,能控制自己总是想把代码设计得大而全的欲望吗?你能无论冬夏每天6点起床10点睡觉,一周运动3次吗?生活中的欲望无处不在,用当下流行的话说,你能保持初心吗?
良好的生活习惯依赖于良好的自控力。这里单独地提出,因为健康对我们太重要了。华为有句话,工作是场马拉松,不是100米,我们不需要时刻冲刺,我们要最后的胜利。工作丢了还能找回来,健康、家庭、感情丟了就再也没有了。最后套用郭德纲一句话: 什么是艺术家?把你熬挂了,我就是艺术家。
凡事保持正向思维
工作了接近10年了,可能是我接触的人不够多,真正能时刻保持正能量的人不多,但也还是有的。
我所谓的保持正能量,不是学雷锋,一不怕苦二不怕累;或者事事佛系,不嗔不怒不喜不悲。那都是概念人,无血无肉。这里想说的是,其实凡事都有正反两面。在逆境中,能看到正面,保持积极向上; 得意时,能看到反面,时刻警醒自己,胜不骄而败不馁。
与人沟通的能力
这个也是职场中被人说烂的一个话题,但是又有多少人能做好?又有多少人能认识到它到底有多难。有句俗语叫,人的心,海底针。根本就琢磨不透。有时候你认为理解了,可是可能对方根本就不是这个意思。有种说法,当两个人在说话的时候,其实有6个人在参与:实际的你,你表达出来的你,对方理解的你,实际的对方,对方表达出来的他,以及你理解的对方。所以,时刻注意保持open状态,不要认为你完全理解了对方的话,误解不可能被消除,只能被减少。当你对别人说话时,也不要指望他能完全理解你的用意,时刻保持校准,才是理想的方式。当交流一段长时间的感悟时,鉴于阅历的不同,更不要指望一次能讲清楚,保持不断地交流与分享才是王道。
不过还是那句话说起来容易,做起来难。人总是武断地,总是趋向于用0/1来区分世界。要么理解了,要么不理解。理解了就想当然地按照自己的想法去做,不理解就暴跳如雷(或者灰心丧气),心里骂一句:傻逼!讲得什么乱七八糟的!
与君共勉,切记,切记。
写了这么多,想说的其实也很简单,工作多年的我们除了技能傍身,修炼自己才能提高核心竞争力。附言中驳斥一下三点劣势。之所以不收入正文,也是借以表达,只要我们做好自己,所有劣势不攻自破。寥寥数言,与君共勉。
附:
关于三点劣势
时间不自由,不利于加班
年轻人积极上进是好事,这也给我们这些老腊肉无形的压力。这个要承认,时间确实是年轻人的优势。老员工当以积极的心态去面对。不要懈怠,否则被赶超是迟早的事儿。但也不必惶恐。因为产出的主导因素是效率,并不是绝对时间的投入(会另开篇来探讨)。如何保证每天的高效时间,远比加多少班重要。
技术落伍了,不能接受新事物
技术这件事本来就是动态的,尤其近几年新技术层出不穷。做软件的很容易让人感受到隔行如隔山。做底层软件的,可能连上层软件用到的名词你都没听过,即便你们用同一种语言开发。但是你有没有想过,就以编程来讲,虽然编程语言千千万万,各种框架更是数不胜数,但他们的基础变过吗?哪种语言或框架要做的不是对现实世界的抽象?哪种技术不用调试解决bug?哪种技术产生不是为了解决现实的问题?所以技术表面的落伍并不可怕,保持对技术终极奥义的探究才是宝贵的。
潜力不足,言下之意,不再愿意学习来提升自己
人本能是趋利避害的,所以心理上会本能地安于舒适区。年长者易保守,因为他们的阅历更多,心理舒适区更大; 年轻者经验少,舒适区更小,表现出易于接受新鲜事物。但这并不是绝对的。推动人持续地走出心理舒适区的,一定是源于内心的,对终极奥义的渴求。这通常与年龄无关。有些人少年成名,有些人大器晚成。活到老学到老。孰不见姜太公80佐文王,齐向石40学印60学画,90方成丹青妙笔。
Deep Learning (15) - RNN & LSTM
这是吴恩达五门Deep Learning课程的最后一门。开篇第一周的课程就是著名的RNN和LSTM。这两个模型都是为了解决序列模型的问题。典型的序列模型问题如下:
 - RNN & LSTM/1538908031365.png)
挨个翻译一下:
- 语音识别
- 音乐发生器
- 评论识别
- DNA序列识别
- 机器翻译
- 视频动作识别
- 名字识别
这些问题都有一个共同点,输入或输出都有可能是一个时间序列。例如语音识别,输入就是一个连续的音频在时间上的序列,视频动作识别也是类似的。音乐发生器没有输入,输出是一段音频,也就是声音在时间上的序列。其他几个输入是一段包含语义的文字,输出是识别的结果。通常包含语义的文字也是时间上的序列,文字只有形成时间上的序列才会有含义。
为什么要有序列模型
序列模型通常包含时间上的连续数据。当然,我们仍然可以采用经典的神经网络模型。那就要求输入包含所有时间上的切片以及不同的步长。
经典模型输出通常是同等维度的输出,而序列模型问题,输出有可能是不同的长度。例如语音识别,同样长度的音频,识别输出文本可能有长有短。如果采用经典模型,则要求输出补偿成相等长度。例如,估计一个最大长度,然后将不足的长度以0补足。
因为序列模型问题,时间上较后的输入受到较前的输入的影响,而经典神经网络没有这部分信息,理论上通过统计学角度,仍然能够达到最终的预测结果,但计算量可想而知,实际也是没有使用价值。这也就是引入序列模型算法的必要性。RNN和LSTM就是两个善于解决序列模型问题的较为常用的算法。
RNN
注:本章所有的例子都是基于解决NLP(Native Language Processing自然语言处理)问题进行阐述的。
基本模型
问题:
检测出文字中的名字字符串
输入:
Harry Potter and Hermione Granger invented a new spell.
首先有一个字典向量,通常这个字典包含10-15万个单词。每一个单词是 - RNN & LSTM/SVGddf8b6376f1f9f2591dc59d8f1ee5ec0)
 - RNN & LSTM/SVG5df3c8c1b098636d57cf18388580440b)
 - RNN & LSTM/SVG6ab625591ae65fe48ae243b4430c5f1e)
输出是:  - RNN & LSTM/SVGa1bf42bfc71f2b8baff4404f1b3c7516)
也就是是名字的单词输出为1,否则为0。
Forward Propagation
 - RNN & LSTM/1538919781321.png)
通常令
其他类型的RNN
Many-to-one (Sentiment classification)
 - RNN & LSTM/1538953445104.png)
One-to-many (Music generation)
 - RNN & LSTM/1538953501761.png)
Many-to-many (
 - RNN & LSTM/1538953612909.png)
Many-to-many ( - RNN & LSTM/SVG7b39fb4bcbb4373eef615e7c699fbf9b)
 - RNN & LSTM/1538953571706.png)
Backward Propagation
这里的反向传播又称为Backward Propagation through time。
 - RNN & LSTM/1538952837860.png)
上图中蓝色的箭头是正向传播,红色的箭头是反向传播
RNN应用举例: Language Modelling & Sequence Sampling
Andrew花了两个视频介绍了Language Modelling和Sequence Sampling。后者基于前者来生成语句。两者均基于由RNN训练出来的模型。一个基本的RNN网络如下,在应用之前,我们需要输入大量的文本进行训练
 - RNN & LSTM/1539138095181.png)
Language Modelling
当训练完毕后,我们可以用下面的网络结构进行modelling。
 - RNN & LSTM/1539137888586.png)
与训练时的网络不同的是,这里没有样本输入,即:
 - RNN & LSTM/SVG6b577044808c9d0dec431457a5cf2c01)
 - RNN & LSTM/SVG2a2557294e85a603242e5d2672ce409a)
 - RNN & LSTM/SVGeab6eb3dfbcee66923085da369f14556) )的概率就是:
)的概率就是:  - RNN & LSTM/SVGa70637d34da87f3f05ee2c08756fe230)
Sequence Sampling
当得到每个时刻t的softmax输出时,运用np.random.choice即可产生一个此时刻的单词 - RNN & LSTM/SVG7ba04e1a53e215e881d64a13011c4cbd)
<EOS>的或者产生足够数量的单词的时候,sampling终止。
如果training set使用的是各种News,则产生的sequence读起来就和新闻一样。如果training set使用的是莎翁的作品,产生的sequence就会像出自莎翁的戏剧。
Character-level language model
这种model的字典向量从所有的词,变成字母+标点符号。字典向量维度大大降低。RNN模型将用来预估每一个字母后面出现字母的概率。
pros
- 不会出现
<UKN>(未知单词),因为全是字母和标点符号。
cons - RNN的序列很长,所以计算量较大。
- 句子通常需要单词间语义的关联,如果以字母为预测单位,则损失了这一有用的信息
Vanishing Gradient
当序列问题的序列足够长的时候,实际也就是RNN网络的层数很多的时候,同标准神经网络一样,会遇到梯度爆炸(exploding gradient)和梯度消失(vanishing gradient)的问题。但是序列问题,又恰恰需要解决这一问题。例如这句话The cat, which already ate …, was full.。主句谓语was需要按照主语是否复数来定。如果中间的从句可能很长,且发生梯度消失问题,则后续 - RNN & LSTM/SVG2e1c2d3ff6cb4c37870849bc22f57f75)
 - RNN & LSTM/SVG72670153a5ed431dd64b85c7f2a6b31e)
梯度爆炸通常比梯度消失容易解决,只要为梯度值设置一个上限即可,就不会导致梯度值变成NaN。但梯度消失通常不太好解决。
GRU
 - RNN & LSTM/1539162264045.png)
是memory cell,在GRU中记录激活值,即
是t时刻c的更新备选
是更新门,决定是否用
是相关门,代表
和
- 所有的W,b都是learnable parameter
代表element-wise相乘
 - RNN & LSTM/SVG419239d4a013b3835649849cbb3d9880)
图中是simplified版本的GRU,没有
LSTM
 - RNN & LSTM/1539164098789.png)
 - RNN & LSTM/SVGec07f12bf21d15a9fefdf1e1b1e227c9)
 - RNN & LSTM/SVGa92ed78253dfc658b7f61b238d33b01c)
 - RNN & LSTM/SVG32e91d967334fb6b8dc3db4285090555)
 - RNN & LSTM/SVG7c6c7b71ef7cb79d92fad6921e35ca7f)
 - RNN & LSTM/SVG8664abfb9a68363cbaa993b8403302d3)
 - RNN & LSTM/SVG68e4d595d6ebedd42338c3584845eba4)
:遗忘门
: 输出门
LSTM通常有很多变种,一个比较著名的变种就是在计算3个
时,加入了
在深度学习的发展中,LSTM很早就被提出,GRU反而相对较晚。GRU的特点是运用门数较少(2个),计算较快,适合搭建更大型的序列模型。LSTM有3个门控制,灵活性更大,但通常计算量也较大。
Bidirectional RNN
先举个name entity recognition的例子:
He said, “Teddy bears are on sale!”
He said, “Teddy Roosevelt was a great President!”
这两个句子,第一句中的Teddy不是名字,第二句中的Teddy是名字。
 - RNN & LSTM/1539165068192.png)
当这个网络里输入到Teddy了,怎么判断是不是一个名字的一部分呢?如果只通过前面输入的部分是无法判断的。必须要借助后面的语句才可以正确的判断。所以就有了双向循环网络的必要了。
最终网络结构如下图:
 - RNN & LSTM/1539165232978.png)
中间紫色的路径是标准的RNN,绿色的路径是反向路径。紫色和绿色的模块都可以采用GRU或者LSTM单元。通常在NLP的应用中,采用LSTM的双向网络是比较常见的。
Deep RNN
对于RNN来说一般很少像CNN那样堆叠很多层,3层对RNN来说就已经非常庞大了。如果需要堆叠多层,一般会删去水平连接。 每个RNN单元可以是标准RNN单元,也可以是GRU单元、LSTM单元甚至BRNN单元,可以自由设置。
 - RNN & LSTM/1539165553848.png)
如上图所示,
参考文献
GRU:
- Cho et al., 2014. On the properties of neural machine translation: Encoder-decoder approaches
- Chung et al., 2014. Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling
LSTM: Hochreiter & Schmidhuber 1997. Long short-term memory
Deep Learning (14) - Neural Style Transfer
这是当下很流行的一个玩法。下面就是一个例子:
 - Neural Style Transfer/1538285228968.png)
将原本的风景照片融入梵高星空画作的风格。还有时下国内很流行的脸萌,化妆的app,应该也是基于这个实现的。
算法步骤
要合成这样一张混合风格的图片的步骤大致如下:
- Initiate G randomly
- Use gradient descent to minimize J(G)
其中:
 - Neural Style Transfer/SVG984e9e03ac78a191a09b55f21225b073)
,
是超参数
- C代表Content,S代表Style,G代表Generated
- Say you use hidden layer l to compute content cost.
- Use pre-trained ConvNet. (E.g., VGG network)
- Let
and
be the activation of layer l on the images
- If
 - Neural Style Transfer/SVG85bb15190fc5cc6b850cda1eab3b8d7f)
 - Neural Style Transfer/SVG8e9b309b7301cb742fa8038334628e22)
图片的风格往往隐含在通道中。我们先看看一个深层卷积神经网络,每一层激活函数输出的数据是什么样的。
 - Neural Style Transfer/1538292610814.png)
上图是网络层有浅及深的数据片段。其中每9个格子代表一个神经元输出。如果放大看,可以发现,浅层网络关注的都是一些局部的线条或者图案。越往深层,图像越具体,3/4/5层已经可以看到具体的物体形态了。
那么,计算风格损失函数,就会是下面这样一个过程:
 - Neural Style Transfer/1538292884877.png)
- 针对第l层,计算其风格损失函数
 - Neural Style Transfer/1538292978497.png)
- 将该层激活输出的volume切片,计算Style Image与Generated Image的correlation
- 计算损失函数
- 总体的风格损失函数就是: 其中
是一个超参数,用来调节每一层的权重。
 - Neural Style Transfer/SVG8cb89c39aa38b50867dbc8ffd4188213)
 - Neural Style Transfer/SVG6310165a7a15b28956842880b207860a)
 - Neural Style Transfer/SVG1363f7b6cfb2cba21655839c6e705913)
 - Neural Style Transfer/SVG49e6c9985576c5213d53c1c8291d5a3c)
参考文献
Neural Style Transfer: Gatys et al., 2015, A neural algorithm of artistic style